Cześć.
Ja nazywam się Kacper Szurek i witam Cię w pierwszej części z cyklu OWASP Top 10.
OWASP to otwarta fundacja, której głównym celem jest poprawa bezpieczeństwa aplikacji webowych.
Organizacja ta prężnie działa i posiada około 100 lokalnych oddziałów na całym świecie.

W ramach swoich działań tworzą wiele projektów, które mają za zadanie zwiększyć świadomość na temat bezpieczeństwa.
Jednym z najbardziej znanych projektów jest OWASP Top 10 czyli zbiór 10 najistotniejszych i najpopularniejszych błędów w zabezpieczeniach aplikacji internetowych.
I każdy z punktów na tej liście to nie jest jedna, konkretna podatność - a bardziej wiele podatności, mających wspólne źródło.
Można więc pokusić się o stwierdzenie, że ta lista to pewnego rodzaju biblia dla programisty.
Jeżeli zrozumiesz na czym polegają te błędy i jaka jest ich istota oraz źródło - będziesz w stanie pisać bezpieczniejszy kod.
Chociażby XSS - czyli wykonanie nieautoryzowanego kodu JavaScript w obrębie podatnej strony.
Rozumiejąc dlaczego jest to niebezpieczne i co jest powodem tego błędu, pisząc swoją aplikację i wyświetlając dane od użytkownika - wyszukasz odpowiednią funkcję w manualu danego języka czy też frameworka, która ochroni właśnie przed tym.

Ta seria będzie wyglądała nieco inaczej niż wszystkie inne dotychczasowe filmy na tym kanale.
Jeżeli oglądałeś już materiały z serii "od 0 do pentestera", mogłeś zauważyć że każdy z nich dotyczy jednego, konkretnego błędu.
Tam, zakładam już, że masz pewne doświadczenie z bezpieczeństwem i rozumiesz niektóre tematy oraz słownictwo, którego używam.
Chociażby Injection czy też CSRF.
Ale wśród osób odwiedzających ten kanał jest też spore grono, które dopiero zaczyna swoją przygodę z bezpieczeństwem.
I ta seria powstała właśnie dla nich.
Celem jest z grubsza opisanie każdego z 10 punktów z listy OWASP.
Dzięki temu po całym kursie powinieneś uzyskać ogólną wiedzę, którą będzie można następnie konkretyzować - doczytując bardziej dokładnie o tematach, które Cię zainteresują.
Nie przedłużając - pora na pierwszy punkt - czyli Injection1 a tłumacząc to na nasz rodzimy język - wstrzyknięcie.

Ten rodzaj błędów ma miejsce jeżeli nie traktujemy danych od użytkownika jako potencjalnie niebezpiecznych i ich odpowiednio nie filtrujemy.
Odpowiednio spreparowane dane, które nie zostały przez nas zabezpieczone mogą prowadzić do zwrócenia innych rekordów, niż moglibyśmy tego oczekiwać.
Myślę, że w Twojej głowie może się teraz pojawić pytanie - ale dlaczego mam traktować użytkownika jako kogoś złego?
W security zawsze powinniśmy rozważać najgorszy możliwy scenariusz.
I zapewne prawdą jest, że 99 procent użytkowników danego serwisu będzie używało go zgodnie z przeznaczeniem.
Ale zawsze znajdzie się ten jeden procent, który będzie spróbował coś zepsuć.
Przykład banku, gdzie można wyszukiwać swoje przelewy.
Jako klient nie byłbyś zapewne zadowolony, gdyby nagle inna osoba lekko modyfikując parametry uzyskała dostęp do Twojej historii.
A dane od użytkownika stanowią idealne miejsce do prób dla atakującego.
Czasy, w których strony internetowe były statyczne i wyświetlały jedynie wcześniej przygotowany tekst i zdjęcia już dawno minęły.
Teraz każdy chce mieć możliwość ingerencji w serwis - czyli jego personalizowanie.
Każdy użytkownik przekazuje więc różne parametry, które następnie są odpowiednio przetwarzane po stronie kodu.
I każdy taki parametr powinien być odpowiednio przefiltrowany - w zależności od tego jakie jest jego przeznaczenie.
Popularną formą przetrzymywania informacji jest baza danych i nie ma tu znaczenia czy mówimy o MariaDB, PostgreSQL czy Oracle.
Oczywiście inaczej zabezpiecza się zapytanie do bazy danych a inaczej zapytanie do serwera LDAP, ale wszystkie mają za zadanie wyświetlić jakieś dane.
I wszystkie te zasoby zawierają dane na różne tematy.
Nie każdy użytkownik powinien posiadać dostęp do nich wszystkich.
Jeżeli więc jest w stanie przekonać bazę do zwrócenia danych, do których normalnie nie ma dostępu - dochodzi do iniekcji.
Ale jaki jest powód, ze użytkownik jest w stanie zwrócić rekordy na przykład z innej tabeli niż ta, zaprojektowana przez programistę?
Do wyciągania danych służą zapytania, w który to używamy danych od użytkownika.
Wszak jak inaczej mielibyśmy zapytać bazę o jakieś słowo kluczowe, które chce zobaczyć użytkownik - bez jego podawania?
To słowo kluczowe musimy jakoś dodać do naszego wcześniej stworzonego zapytania.
I jeżeli dopiero rozpoczynasz przygodę z programowaniem - jedną z opcji, która może Ci się wydać słuszna - jest zwykła konkatenacja czyli połączenie takiego ciągu z zapytaniem.
A to jest niebezpieczne.
W zapytaniach gdy wyszukujemy jakiegoś tekstu - musimy go zawrzeć pomiędzy pojedynczymi albo podwójnymi cudzysłowami, tak aby baza danych wiedziała, że nie jest to dalsza treść zapytania - ale jego parametr.
Wszystko będzie działało prawidłowo w większości przypadków - problem pojawi się jednak, jeżeli użytkownik będzie chciał wyszukać jakieś zdanie, w którym znajduje się cudzysłów.

Dlaczego? Ponieważ ten jego cudzysłów zostanie potraktowany jako cudzysłów zamykający ciąg znaków podanych w zapytaniu, sprawiając tym samym że cały tekst po cudzysłowie zostanie potraktowany jako dalsza część zapytania.
A to w większości przypadków zakończy się błędem.
Dlaczego? Zapytanie ma pewną sformalizowaną składnię i większość słów z dowolnego języka po prostu do tej składni nie pasuje.
Ale tu omawiamy przykład użytkownika, który po prostu dla wyrazów z cudzysłowem nie dostanie wyników.
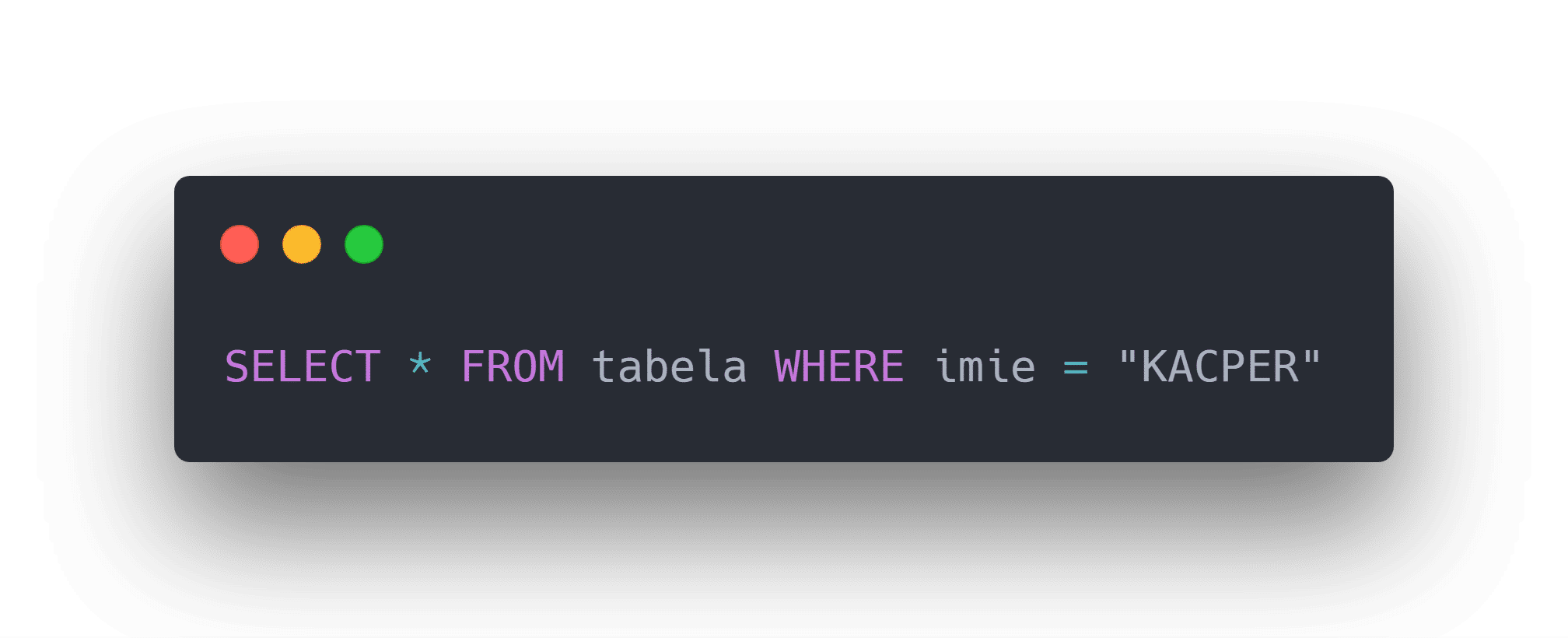
A co jeżeli atakujący może spreparować dane, przesyłane po cudzysłowiu?
Nic nie stoi bowiem na przeszkodzie aby dodać tam słowo kluczowe OR 1=1.

OR oznacza "lub", czyli zapytanie będzie wyświetlało wyniki zgodne z pierwszą częścią parametru lub zgodne z drugą częścią.
1=1to warunek logiczny, który jest zawsze prawdą, a to sprawi, że każdy rekord w tej bazie będzie pasował do tego warunku, czyli zostanie zwrócony dla atakującego.
Tutaj omawialiśmy wstrzyknięcie do parametru WHERE, ale to nie jedyne miejsce gdzie można coś zepsuć.
Innym często omijanym miejscem jest sortowanie.
Jeżeli to użytkownik przekazuje nazwę kolumny, po której mają zostać posortowane rekordy - to tam również można dopisać dalszą część zapytania.
Jak zatem ochronić się przed atakiem SQL Injection - czyli wstrzyknięciem danych do zapytania do bazy danych?
Najlepszym rozwiązaniem są tak zwane prepared statements.

Oczywiście implementacja różni się w zależności od języka - ale schemat zostaje ten sam.
Tym razem, żadne dane od użytkownika nie są przekazywane do zapytania wprost.
Programista zaznacza jedynie miejsca w zapytaniu, w których mają się znaleźć dane od użytkownika.
Zazwyczaj do tego celu używa się pytajnika.
Następnie wywołuje odpowiednią funkcję, do niej przekazując parametry od użytkownika.
I to właśnie ta funkcja sprawdza zapytanie w poszukiwaniu pytajników i zamienia je na dane od użytkownika.
Oczywiście uprzednio odpowiednio je filtrując i zabezpieczając - tak aby nie można już było wstrzyknąć żadnego innego warunku.
Dzięki takiemu podejściu do tematu to programista ma pełną kontrolę nad zapytaniem a użytkownik może jedynie zmienić te parametry, na które pozwolił mu projektant.
Ale bazy danych to nie jedyne miejsca, które są zagrożone.
Innym bardzo popularnym miejscem, do którego można dodać swoją złośliwą wartość jest command injection, szczególnie często spotykane w różnej maści urządzeniach IoT.
Czasami zdarza się, ze niektóre funkcjonalności potrzebne do naszego projektu są już stworzone w innym języku niż ten, którego obecnie używamy.
Wtedy to też, musimy się do nich jakoś odwołać.
Weźmy pod uwagę chociażby pakiet imagemagic2, który pozwala wyświetlać, tworzyć, modyfikować i zapisywać pliki graficzne w wielu formatach.

On to dostępny jest pod Linuxem jak plik wykonywalny.
Aby zatem z niego skorzystać musimy z poziomu naszej aplikacji wywołać właśnie tą komendę.
Pomijam już fakt, że powinniśmy unikać takich konstrukcji jak ognia - ponieważ są prostą metodą na stworzenie błędów bezpieczeństwa.
Ale załóżmy, że z powodu różnych ograniczeń jesteśmy zmuszeni do takiego zachowania.
Każdy język posiada jakąś funkcję, która umożliwia przesłanie tekstu do linii komend i zwrócenia jej wyniku.
Może to być funkcja system, exec, shell, eval, passhthru, popen, shellexecute.
I tutaj również programista konstruuje ciąg znaków, który jest komendą, która ma zostać wykonana.
Jeżeli użytkownik kontroluje jakiś parametr - na przykład wielkość obrazka - to ten parametr również musi zostać przekazany do tej komendy.
I znowu jeżeli użyto zwykłej konkatenacji - ponownie atakujący kontroluje całą komendę.
W Linuxie bowiem jeżeli w komendzie występuje średnik, system operacyjny otrzymuje informację, że jest to koniec bieżącej komendy i wszystko co następuje po średniku jest nową komendą.
W taki oto sposób można dokończyć przekazywanie parametrów do komendy zaprojektowanej przez programistę i wywołać dodatkową złośliwą - wybraną przez nas.
Zatem powodem występowania tego błędu jest przekazywanie jednego długiego ciągu znaków - komendy - do funkcji systemowej.
A można to zrobić inaczej, bezpieczniej.
Zazwyczaj te funkcje posiadają dodatkową składnię, w której to można rozdzielić parametry przy użyciu listy.
Wtedy to nie przekazuje się jednego długiego ciągu znaków a listę.
Pierwszym elementem listy jest nazwa komendy a każdy kolejny to parametr.
Wtedy to język tak przetworzy dane przekazane od użytkownika, aby były one traktowane przez komendę jako parametr - a nie jako inna, dodatkowa komenda.
Dzięki temu nawet jeżeli użytkownik przekaże średnik, to zostanie on potraktowany jako średnik - czyli dla przykładu rozmiar obrazka zostanie ustawiony na średnik.
Oczywiście taki parametr zwróci błąd i operacja zmiany rozmiaru się nie powiedzie - ale tym samym nie wykona się inna komenda.
Warto również zwrócić uwagę, że dalej w takim podejściu nie chronimy przed przekazaniem złośliwego parametru do danej komendy.
Jeżeli więc imagemagic posiadałoby opcję wykonuj, która uruchamia dowolny program przekazany jako parametr - złośliwy atakujący mógłby nadal przekazać taki parametr do tej komendy i w taki sposób uruchomić złośliwy kod.
W takim podejściu wszystko zależy od komendy którą uruchamiamy i od funkcjonalności, które posiada.

Osobną podkategorią są błędy "blind" (ślepe) - czyli takie, które nie zwracają swoich wyników bezpośrednio.
Nie wszystkie zapytania wykonywane po stronie serwera zwracają dane użytkownikowi.
Wtedy to atakujący musi w inny sposób dowiedzieć się, jakie dane zostały zwrócone podczas ataku.
Najpopularniejszą metodą jest użycie czasu.
Każde zapytanie do serwera trwa.

Jeżeli wszystko jest dobrze zaprojektowane i działa bez większych błędów - czasy odpowiedzi są krótsze niż jedna sekunda.
Ale większość języków czy też baz danych posiada funkcję pozwalającą czekać jakiś czas.
I to właśnie te funkcję są wykorzystywane w exploitacji błędów typu blind.
Oczywiście ma to swoje ograniczenia. Możemy zadawać jedynie pytania "tak czy nie".
Dla przykładu: sprawdzamy, czy pierwsza litera hasła użytkownika admin to x.
Jeżeli tak - wykonujemy funkcję sleep(5) - mającą czekać 5 sekund.
Jeżeli nie - nic nie robimy.
Wysyłając takie żądanie do serwera - sprawdzamy czas odpowiedzi.
Jeżeli jest poniżej sekundy - oznacza to że hasło nie zaczyna się na literę x.
Jeżeli trwało więcej niż 5 sekund - wiemy, że trafiliśmy i możemy przejść do sprawdzania kolejnej litery.
Oczywiście nikt nie robi tego manualnie a wykorzystuje różne gotowe rozwiązania, dla przykładu SQLmap3, który automatyzuje ataki SQL injection.
Powoli zbliżamy się do końca tego segmentu.
Warto zwrócić uwagę, że miejsc potencjalnych iniekcji danych od użytkownika jest jeszcze kilka.
Mniej popularnym jest XPath Injection4, kiedy witryna pozwala na wyszukiwanie danych z plików XML.

Tam również znajduje się pewnego rodzaju język, który pozwala na pobieranie danych z konkretnych pól tych plików.
A atakujący - jeżeli zapytanie nie jest odpowiednio filtrowane - może przekonać aplikację do wyświetlenia całego pliku.

Albo LDAP Injection5, czyli protokół przeznaczony do korzystania z usług katalogowych takich jak Active Directory, z którym możesz spotkać się w środowisku korporacyjnym, kiedy to dane na temat użytkowników nie są przechowywane w osobnej bazie a w jednym, wspólnym miejscu.
I to już wszystko w tym odcinku.
Podsumowując: zawsze traktuj dane od użytkownika jako potencjalnie niebezpieczne i filtruj je w zależności od miejsca docelowego, w którym mają być wykorzystane.
Zapraszam Cię do kolejnego odcinka z serii OWASP Top 10, w którym opisywać będę niepoprawną obsługę uwierzytelniania i sesji.
Free B-Roll provided by http://www.videezy.com/
Computer Hard Drive by Beachfront CC BY 3.0
Icon made by Freepik www.flaticon.com
![[OWASP Top 10] A10](https://img.szurek.eu/v7/_thumb_/1/1/8/1182/owasp-10.png?w={width})
![[OWASP Top 10] A9](https://img.szurek.eu/v7/_thumb_/1/1/7/1172/owasp-9.png?w={width})
![[OWASP Top 10] A8](https://img.szurek.eu/v7/_thumb_/1/1/6/1161/owasp-8.png?w={width})