Cześć.
To już 3 odcinek z serii OWASP Top 10, w której opisuję najpopularniejsze rodzaje błędów występujące na serwisach internetowych.
Dzisiaj o ekspozycji wrażliwych danych - czyli o wydobyciu przez atakującego informacji, których nie powinien posiadać.
A jest ich wbrew pozorom całkiem sporo: począwszy od numeru kart kredytowych, haseł do konta, adresu email, daty urodzenia, czy też informacji na temat naszego stanu zdrowia.
Różne są ryzyka związane z wyciekiem różnych danych.
I tak - jeżeli wyciekną numery kart kredytowych - ktoś może stracić pieniądze z konta.
Poznanie hasła może pozwolić na zalogowanie się do innego serwisu, jeżeli użytkownik używa tych samych danych w wielu miejscach.
Gdy ktoś pozna klucz prywatny stosowany podczas transmisji SSL - może użyć go w ataku man in the middle podszywając się pod naszą stronę internetową.
A nasz adres email może zostać użyty w kampaniach mailingowych, w których to dystrybuowane jest złośliwe oprogramowanie.

Jedną z najważniejszych zasad jaką powinniśmy się kierować, aby uchronić się przed skutkami tego błędu jest przechowywanie jak najmniejszej ilości danych na temat użytkownika.
Chociaż to może być trudne w obecnych czasach, kiedy to z biznesowego punktu widzenia najlepiej zbierać wszystko na temat użytkownika, aby jak najdokładniej go profilować i wyświetlać targetowane reklamy.
Kolejnym ważnym punktem jest szyfrowanie danych - i tutaj rozpatrzyć należy dwa podpunkty - bezpieczne przechowywanie danych oraz ochrona w trakcie ich przesyłania.
Ten drugi podpunkt w obecnych czasach może wydawać się oczywisty - mowa bowiem o protokole HTTPS i szyfrowaniu połączenia.
Jeszcze parę lat temu bardzo mały procent stron był dostępny z poziomu protokołu HTTPS.
Tłumaczenie było proste: szyfrowanie to zwiększony narzut obliczeniowy, a certyfikaty swoje kosztują.
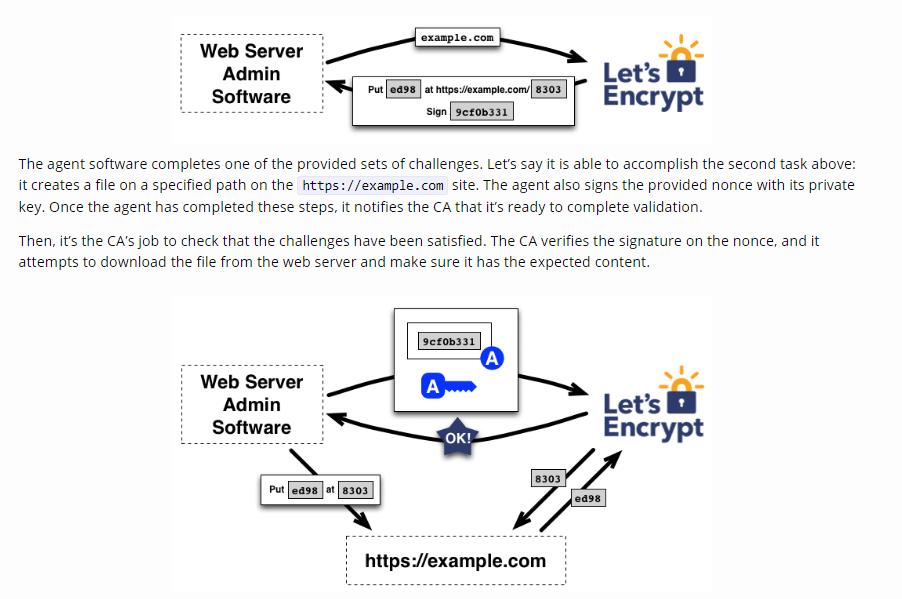
Teraz certyfikaty można generować za darmo - na przykład przy użyciu Lets encrypt1, a obecne komputery są na tyle wydajne, że narzut obliczeniowy jest znikomy.
Również ruchy przeglądarek, które wyświetlają informacje na temat niebezpieczeństwa na danej stronie - jeżeli przesyła one dane przy użyciu HTTP - znacząco przyczyniło się do popularyzacji tego rozwiązania.
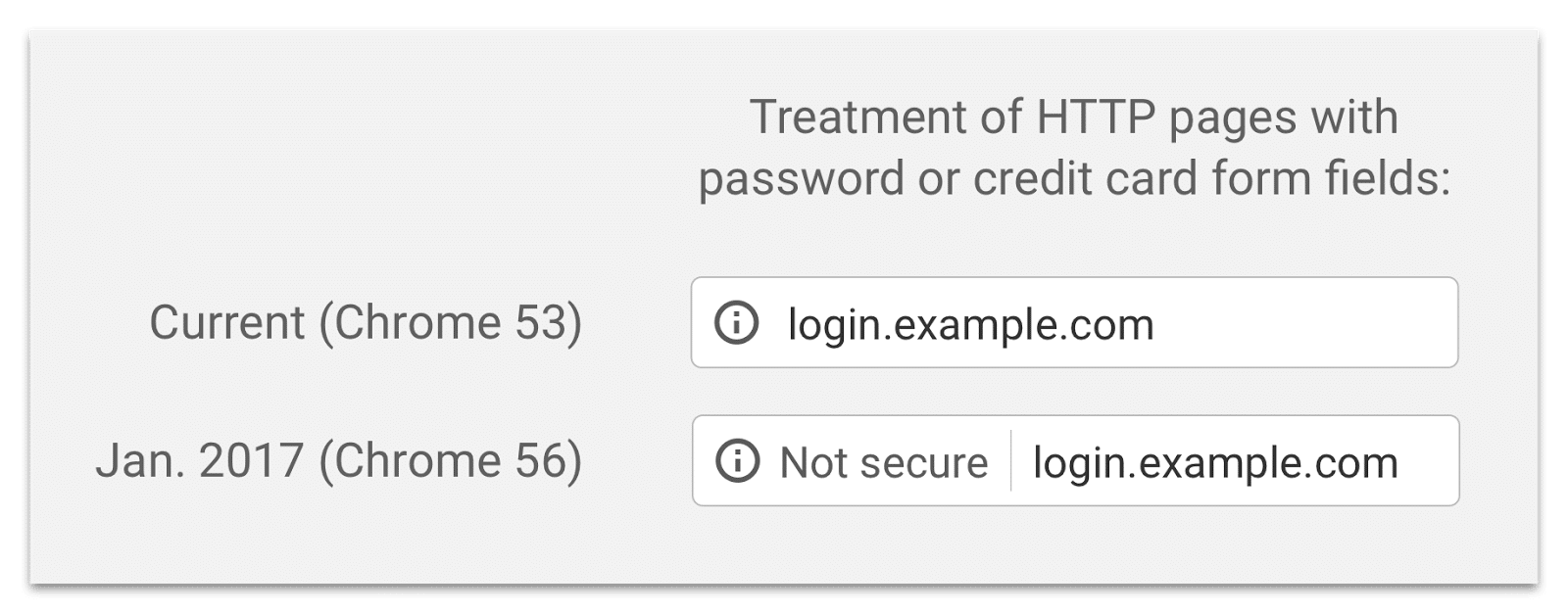
Dlatego też nie ma już usprawiedliwienia, aby tylko strona logowania była szyfrowana.
W tym miejscu warto również wspomnieć o specjalnym nagłówku HSTS.
Gdy nasza strona zwróci taki nagłówek do przeglądarki – od tego momentu nie będzie możliwa komunikacja przy pomocy http.
Przeglądarka automatycznie zamieni ją na tą bezpieczną i to wszystko bez udziału użytkownika.
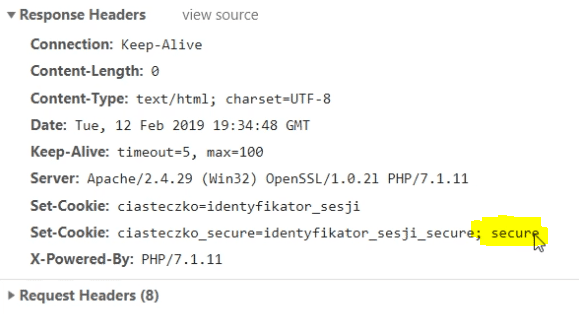
Każde ciasteczko winno mieć ustawioną flagę Secure, która sprawia, że nie zostanie ono wysłane przy użyciu protokołu http.
Co nam bowiem z faktu, że podczas logowania połączenie jest szyfrowane, jeżeli ciasteczko z informacją na temat sesji użytkownika jest przesyłane z każdym żądaniem?
A sesja taka pozwala na zalogowanie się jako dany użytkownik - i to bez znajomości jego hasła.
Ale strony to nie jedyne miejsce, przez które przepływają informacje.
Mamy przecież maile lub też ruch pomiędzy naszymi serwerami.
Rzadko która większa strona jest uruchomiona tylko na jednym serwerze - zwłaszcza w obecnych czasach, gdzie dostęp do chmur obliczeniowych jest znacząco uproszczony.
Mamy więc różne mikroserwisy, Dockery, load balancery - i wszystko to powinno komunikować się ze sobą w bezpieczny sposób.
Nie zapominajmy również o aplikacjach na urządzenia mobilne, które to komunikują się z naszymi endpointami API.
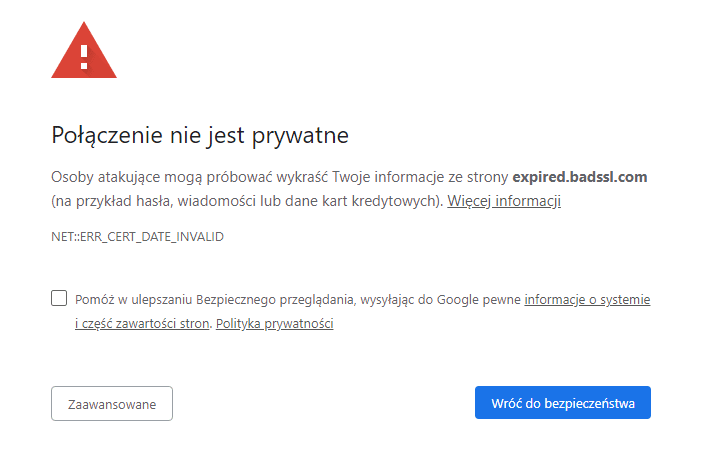
Tutaj kluczowym jest sprawdzanie poprawności certyfikatu.
W przypadku stron - jest za to odpowiedzialna przeglądarka.
W aplikacji jednak to programista musi użyć odpowiednich funkcji, które sprawdzą czy certyfikat jest prawidłowy i wystawiony przez zaufany urząd certyfikacji.
A jest to kluczowe - zwłaszcza, że to użytkownicy telefonów są najbardziej narażeni na ataki man in the middle - kiedy to w różnych sytuacjach życiowych łączą się z darmowymi sieciami Wi-Fi.
Chociażby na lotnisku w obcym mieście - jeżeli aplikacja nie sprawdza certyfikatu, ktoś może w taki sposób wykraść dane.
Pozostając przy temacie certyfikatów.
Z każdym certyfikatem powiązany jest klucz prywatny.
A ten to musi być unikalny i losowy - aby zapewnić odpowiednie bezpieczeństwo.
Znany jest przypadek gotowego obrazu systemu WordPress2, używanego w chmurze DigitalOcean - kiedy to w standardowej konfiguracji certyfikat był wystawiany na wcześniej wygenerowany klucz - co sprawiło, że wiele stron używało tego samego klucza prywatnego, który z założenia powinien być unikalny.
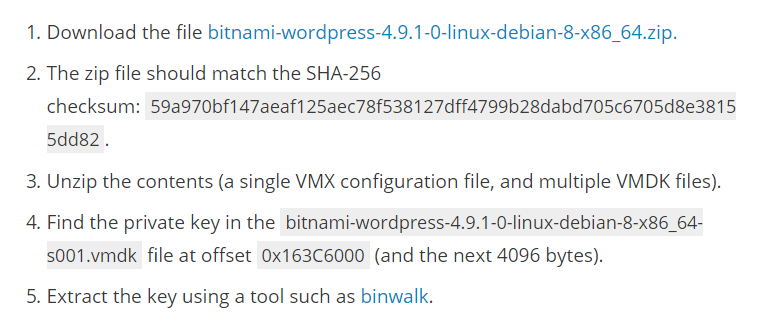
I nie chodzi tu tylko o klucz prywatny, ale także o wszystkie tokeny i sole, używane w obrębie naszej aplikacji.
Powinny one posiadać odpowiednią entropię.
Inny przykład to kopiowanie kawałków kodu służących do szyfrowania danych wprost ze stron w stylu Stack Overflow3 - bez zmiany danych tam zawartych.
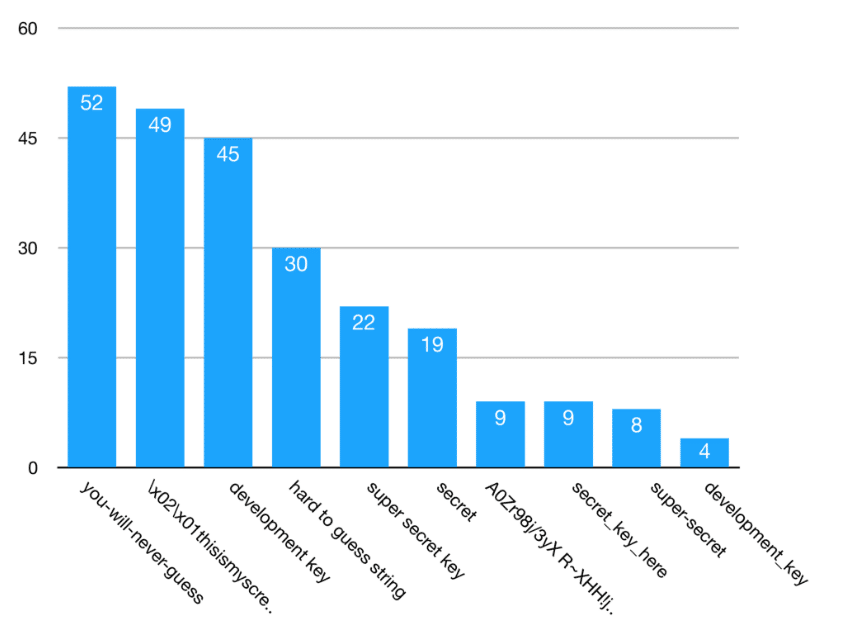
W różnych językach programowania są różne funkcje generujące dane losowe lub, będąc bardziej dokładnym, w większości dane pseudolosowe - czyli takie oparte na ziarnie.
Jeżeli posiadamy wartość początkową - czyli ziarno - algorytmy te są deterministyczne - to znaczy, ze zwracają te same dane wyjściowe dla tych samych danych wejściowych.
Co sprawia, że stają się bezużyteczne w kontekście generowania bezpiecznych kryptograficznie wartości.
Przykładem niech będzie funkcja Random w Javie.
Przykład odzyskiwania tak wygenerowanej wartości można odnaleźć w filmie z cyklu od 0 do pentestera4.

Chodzi również o samo przechowywanie tych kluczy.
Co bowiem z tego, że dane są szyfrowane, jeżeli klucz leży na dysku twardym serwera i każdy atakujący może go zwyczajnie pobrać?
Idealnie byłoby zastosować rozwiązanie sprzętowe, czyli HSM - sprzętowy moduł bezpieczeństwa, który przechowuje i zarządza kluczami w bezpieczny sposób.
Nie da się w prosty sposób wyeksportować klucza z takiego urządzania.
Działa ono bardziej jako API - kiedy to wysyła się do niego jakieś informacje, a w odpowiedzi otrzymujemy wynik operacji kryptograficznej z wykorzystaniem przechowywanego tam klucza.
Oczywiście nie każda firma może sobie pozwolić na tego rodzaju urządzenia.
Chociaż chmura obliczeniowa sprawia, że korzystanie z tego rodzaju modułów jest coraz tańsze.
Ale co z danymi, które już w bezpieczny sposób trafiły do naszego serwera?
Teraz potrzeba je jakoś bezpiecznie zapisać w obrębie naszej infrastruktury.
Oczywistym wydaje się fakt, aby nie przechowywać haseł w tak zwanym plain text, a w formie haszy z solą.
- Sól to dodatkowa losowa, wartość dla każdego konta inna, która łączona jest z hasłem przesłanym przez użytkownika.
I to z całego takiego ciągu generuje się hasz - czyli wynik funkcji jednokierunkowej, i porównuje się go z tym, zapisanym w bazie.
Dzięki temu nawet jeżeli hasze haseł wyciekną - ich łamanie będzie znacząco utrudnione.
Atakujący bowiem będzie musiał łamać każde hasło oddzielnie - ponieważ do każdego hasła doklejana jest inna wartość.

Tutaj również czają się pułapki - w Internecie dalej można odnaleźć sporo miejsc, w których mówi się o algorytmie SHA1 - który jest już traktowany jako przestarzały.
Z roku na rok komputery są coraz szybsze, powstają specjalne jednostki ze sprzętową akceleracją funkcji kryptograficznych.
Dlatego warto zainteresować się funkcjami, które posiadają tak zwany work factor, który jest wartością konfigurowalną.
Jest to liczba, która powiązana jest ze stopniem złożoności obliczeniowej takiego algorytmu.
Jej zwiększenie o jeden podwaja dwukrotnie czas obliczeń.
A zwiększenie czasu generowania hasza do 1 sekundy - dla przeciętnego użytkownika jest niezauważalne, wszak loguje się tylko raz na x dni.
Dla atakującego jednak - generowanie 1 hasza na sekundę to zdecydowanie za mało, biorąc pod uwagę ilość kombinacji, które musi sprawdzić.
To samo tyczy się algorytmów szyfrowania.
Nie wystarczy bowiem używać sprawdzonych algorytmów i bibliotek.
Należy to również robić w prawidłowy sposób.

Tutaj koronnym przykładem jest AES w trybie ECB.
Szyfry blokowe bowiem operują na blokach danych - gdzie dane wejściowe są podzielone na bloki różnej długości.
W najprostszym przypadku, każdy taki blok może być procesowany oddzielnie - co wpływa na wydajność.
Można bowiem szyfrowanie podzielić na wiele równoległych wątków.
Tylko, że jeżeli w szyfrowanej wiadomości znajdują się jakieś regularności - na przykład powtarzalne ciągi danych, to ta sama struktura może się uwidocznić w zaszyfrowanych danych.
Tutaj warto również wspomnieć o padding Oracle - pozwalający na odzyskanie tekstu jawnego z zaszyfrowanych danych i to wszystko bez znajomości klucza.
I to tylko dlatego, że aplikacja zwracała do użytkownika informacje na temat paddingu - czyli danych automatycznie dokładanych do bloku, jeżeli był on zbyt krótki dla danego algorytmu.
Ale dane wrażliwe nie znajdują się tylko na naszym serwerze.
Może się zdarzyć, że przez przypadek udostępnimy je w backupie lub logach, przesyłanych do różnych innych systemów.
Wiele organizacji przechowuje logi w jednym, zcentralizowanym miejscu.
To samo tyczy się kodu źródłowego i kluczy API, które mogą się tam znaleźć.
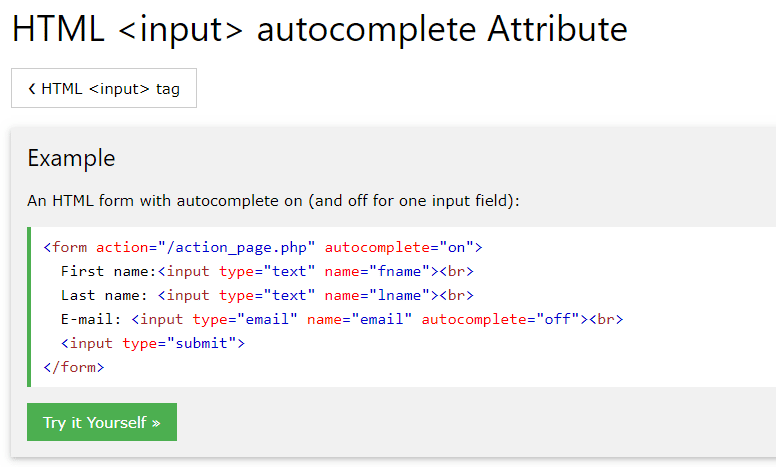
Znanych jest wiele przypadków, gdy ktoś z roztargnienia przesłał kod źródłowy do ogólnodostępnego repozytorium na GitHubie.
Warto też wyłączyć mechanizmy cachowania wszędzie tam, gdzie przesyłane są dane wrażliwe, a także wyłączyć mechanizmy auto uzupełniania w polach, w których wpisywane jest hasło - tak aby przeglądarka użytkownika nie proponowała ich autouzupełniania5.
Teoretycznie prosty temat, a tyle różnych historii.
A ja już dzisiaj zapraszam Cię do kolejnego odcinka z tej serii, w którym porozmawiamy o nowości względem OWASP 2013 czyli o ataku XXE.
Free Broll provided by videezy.com Stock footage provided by Videvo, downloaded from https://www.videvo.net
Icon made by Freepik www.flaticon.com
Design vector created by freepik - www.freepik.com
![[OWASP Top 10] A10](https://img.szurek.eu/v7/_thumb_/1/1/8/1182/owasp-10.png?w={width})
![[OWASP Top 10] A9](https://img.szurek.eu/v7/_thumb_/1/1/7/1172/owasp-9.png?w={width})
![[OWASP Top 10] A8](https://img.szurek.eu/v7/_thumb_/1/1/6/1161/owasp-8.png?w={width})