ResolveURL
Gdzie i dlaczego można odnaleźć wykorzystanie ResolveURL w aplikacjach?

Nasza strona internetowa może być podzielona na wiele plików aspx.
A każdy z tych plików może się odnosić do różnych zasobów: obrazków, plików JS, plików CSS, które mogą się znajdować w różnych katalogach.
Rozważmy taką prostą sytuację: podstrona panelu administratora znajduje się w katalogu root/admin/config.aspx.
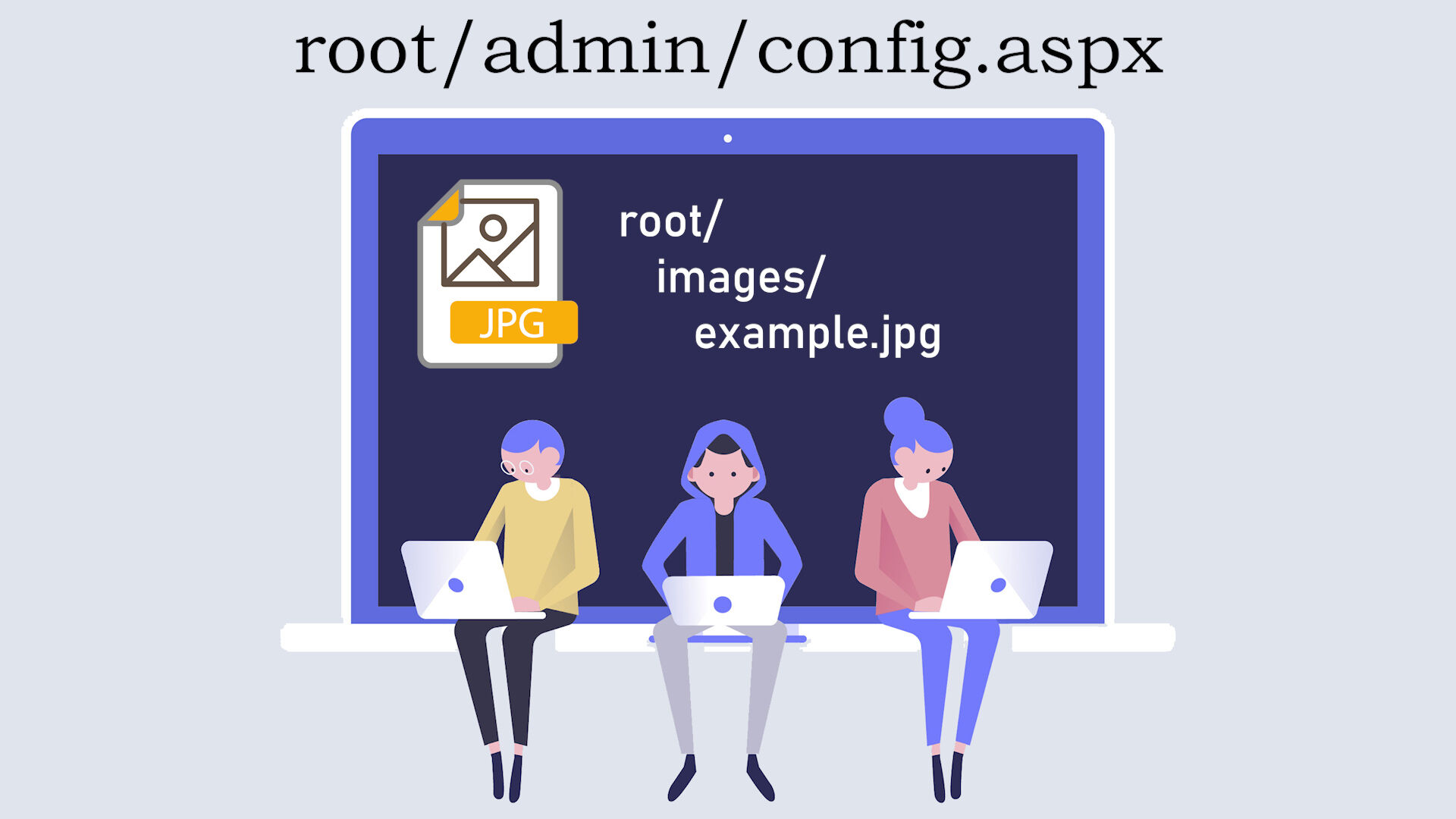
Wykorzystujemy tam obrazek, który znajduje się w zupełnie innym miejscu:
root/images/example.jpgJak możemy się do niego odwołać? Mamy kilka rozwiązań.
1. Zapisanie pełnego adresu obrazka na sztywno w kodzie aplikacji.

To rozwiązanie ma jednak pewną wadę. Co w przypadku, gdy zmienimy katalog główny naszej aplikacji? Albo postanowimy umieścić ją w jeszcze jednym podkatalogu?

Wtedy wszystkie takie wystąpienia należałoby zmodyfikować.
2. Wykorzystanie adresów względnych.
Obecnie jesteśmy w katalogu admin. Chcemy przejść jeden katalogu wyżej w hierarchii - używamy więc ciągu ../.
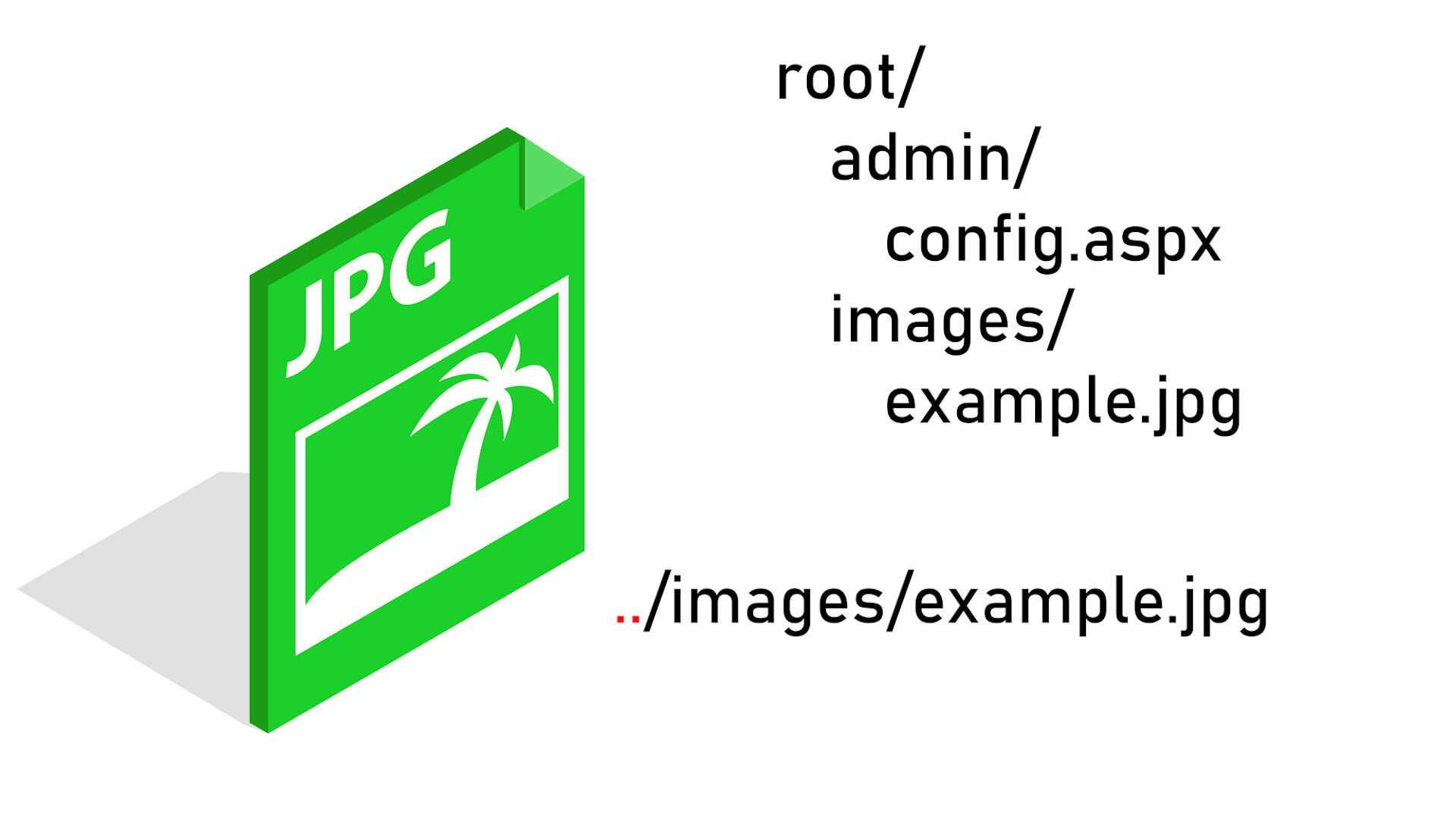
Ale ponownie nie jest to najlepsze rozwiązanie.
W zależności od bieżącego katalogu i katalogu do którego się odwołujemy - będziemy musieli pamiętać o prawidłowej liczbie kombinacji ../.
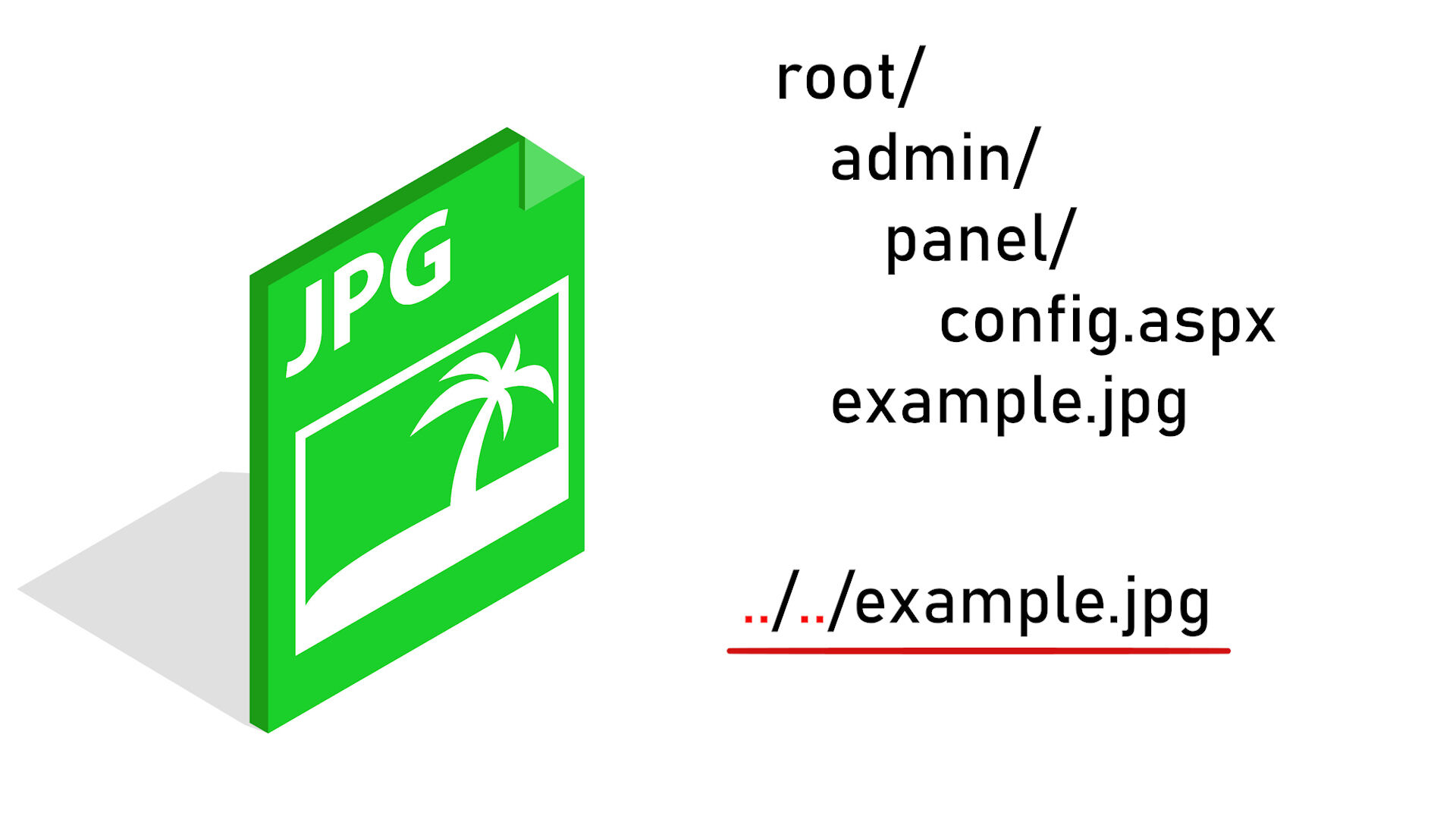
Poza tym, jeżeli postanowimy przenieść podstronę panelu administratora w inne miejsce - katalogi znowu się zmienią.
Dochodzi tu jeszcze kwestia czytelności. Jeżeli programista chce wiedzieć gdzie kieruje dane łącze - musi sprawdzić adres bieżącego pliku i wyliczyć sobie nową wartość dodając i odejmując katalogi.
3. ResolveUrl i znak tyldy.
- Tylda to skrót do wirtualnego katalogu głównego, a mówiąc inaczej: to wartość zmiennej
HttpRuntime.AppDomainAppVirtualPath.

Teraz nasze adresy mogą wyglądać inaczej. Możemy je rozpocząć od tyldy - startując niejako od głównego katalogu.
~/images/example.jpgI to tyle. Wydawałoby się prosta funkcja wykonująca jedną czynność. Co może pójść nie tak?

Jest rok 2005. Tworzymy coraz ciekawsze aplikacje, a to wymaga zapisywania stanu bieżącego użytkownika. W dzisiejszych czasach stosujemy do tego tokeny JWT bądź ciasteczka. Ale wtedy nie było to takie oczywiste.
Istniały przeglądarki które nie akceptowały ciasteczek - bądź też użytkownicy deaktywowali tą opcję.

To sprawiało, że nasza nowoczesna strona przestawała działać. Jak bowiem rozpoznać użytkownika, jeżeli nie możemy przekazać jego identyfikatora poprzez ciasteczko?
I tak narodziła się funkcjonalność Cookieless.
Cookieless
Stwierdzono, że jeżeli przeglądarka nie akceptuje ciasteczek to warto skorzystać z czegoś, co już jest obsługiwane w każdej przeglądarce - czyli pasek adresu.

Wymyślono więc, że identyfikator użytkownika będzie przekazywany w adresie URL.
Wykorzystano do tego pewną specyficzną formę. Zaczyna się ona od nawiasu otwierającego, dalej literki A, S lub F następnie ponownie nawias otwierający, dalej identyfikator oraz dwa nawiasy zamykające.
(A(?)) - Anonymous ID
(S(?)) - Session ID
(F(?)) - Form Authentication TicketPomimo tego iż jest to swego rodzaju archaiczna funkcjonalność - dalej istnieje w ASP.NET.
Całość można kontrolować przy pomocy SessionStateSection.Cookieless.
Standardowa wartość to AutoDetect - co dla większości nowoczesnych przeglądarek internetowych jest równoznaczne z przechowywaniem identyfikatora sesji w ciasteczku.
Funkcjonalność ta miała zapewnić, że identyfikator będzie występował w każdym odnośniku klikniętym przez użytkownika. Bo tylko dzięki temu aplikacja wie z kim ma do czynienia.
Nie dziwi więc, że nasza poprzednio omówiona funkcja ResolveUrl automatycznie dodaje identyfikator do adresu - o ile wykryje jego użycie.
Adres:
http://szurek.pl/aplikacja/home.aspxJest zamieniany na:
http://szurek.pl/aplikacja/(A(XXXX)S(XXXX)F(XXXX))/home.aspxA to jest niebezpieczne.

Dlaczego? Ponieważ funkcja, która wydawałoby się nigdy nie przyjmuje parametrów od użytkownika (no bo przecież ścieżki są zazwyczaj zapisane bezpośrednio w kodzie przez programistę) - nagle pobiera identyfikator z adresu URL i wyświetla go w kodzie źródłowym.
Takie zachowanie może doprowadzić do ataku XSS. Jest to bowiem klasyczny przypadek w którym dane od użytkownika są wyświetlane bez odpowiedniej weryfikacji i walidacji.
Paweł (autor badań) postanowił sprawdzić jakie znaki może zawierać identyfikator sesji.
.NET zwraca błąd 400 dla niektórych znaków, które uważa za nieprawidłowe:
| Znak | Opis |
| > | Większość |
| < | Mniejszość |
| ? | Pytajnik |
| $ | Dolar |
| % | Procent |
Nie zwraca jednak błędu dla spacji oraz pojedynczego bądź podwójnego cudzysłowu. A to jest interesujące.
XSS
Wspomniałem wcześniej, że ResolveUrl używane jest zazwyczaj w odniesieniu do zewnętrznych plików CSS, obrazków lub plików JS.
<script src="<%= ResolveUrl("~/Script.js") %>"></script>
<img src="<%= ResolveUrl("~/image.jpg") %>"
<link rel="stylesheet" href='<%= ResolveUrl("~/style.css") %>'></link>Jeszcze wcześniej traktowaliśmy te linijki jako bezpieczne - no bo nie przyjmowały żadnych parametrów od użytkownika. Teraz wiemy już, że funkcja radośnie kopiuje identyfikator sesji - o ile znajduje się on w przekazanym przez nas adresie oraz nie zawiera nieprawidłowych znaków.
Możemy więc przeprowadzić klasyczny atak XSS.

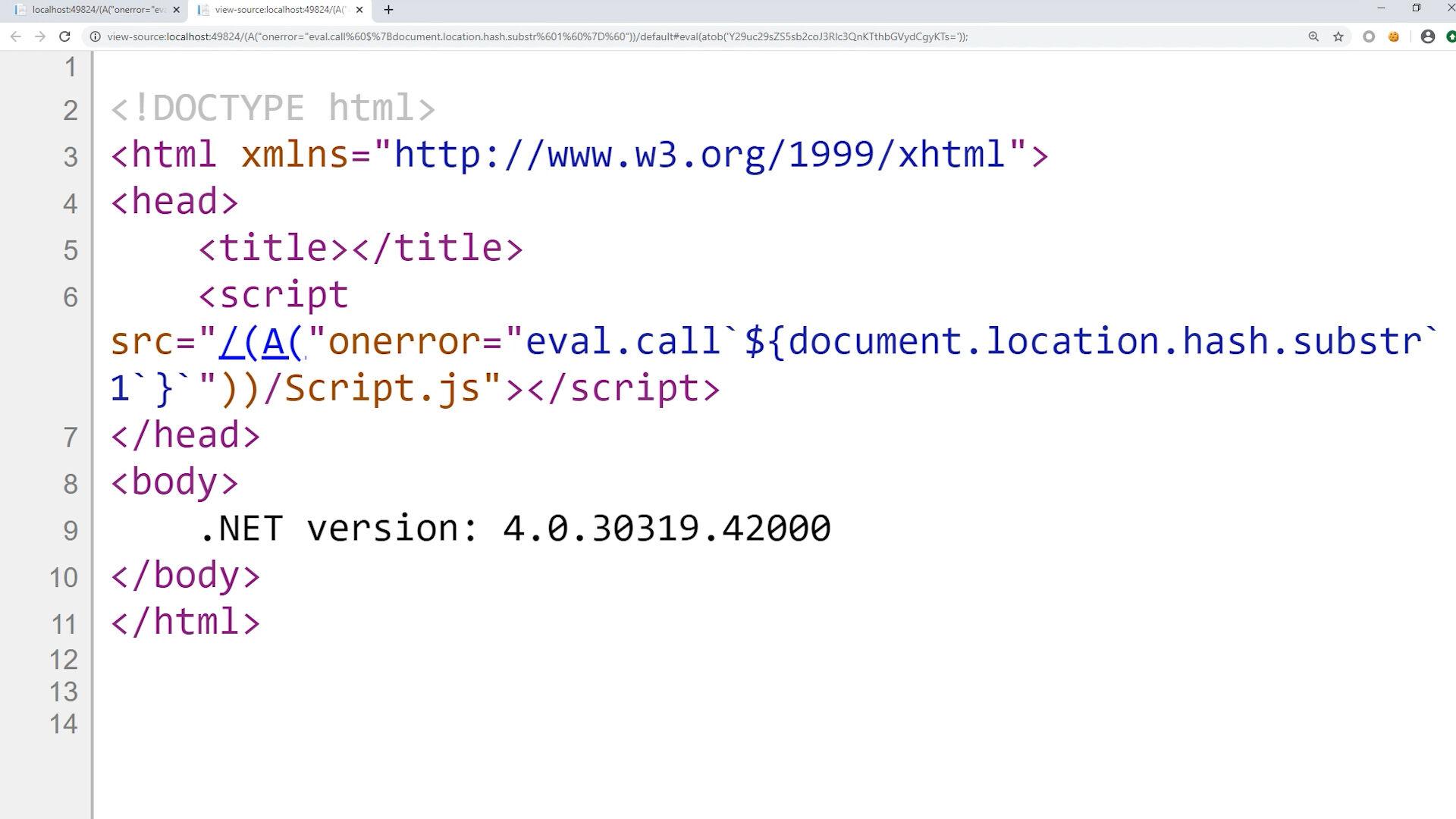
Zamykamy cudzysłów - a dalej wykonujemy event onerror. Adres:
http://szurek.pl/aplikacja/(S(" onerror=alert(1) ))/home.aspxZostanie zamieniony na:
<script src="/(S(" onerror=alert(1) "></script>Czyli przeglądarka spróbuje pobrać obrazek /(S(. Jeżeli go nie znajdzie wykona event onerror - czyli wyświetli okienko alert.

Tutaj natrafiamy jednak na jeden problem. Prawy nawias znajduje się na liście nieprawidłowych znaków. Jak zatem możemy wywołać funkcję alert z parametrem bez używania nawiasów?
Na pomoc przychodzi standard ES6 i nowa opcja zwana template strings.
Backtick w XSS

Zamiast alert(1) możemy dokonać tego samego z użyciem znaku backtick.
http://szurek.pl/aplikacja/(S(" onerror=alert`1` ))/home.aspxZostanie zamieniony na:
<script src="/(S(" onerror=alert`1` "></script>Właśnie udowodniliśmy, że możemy wykonać dowolny kod JavaScript w obrębie danej strony internetowej. Jest to więc klasyczny przykład ataku XSS.
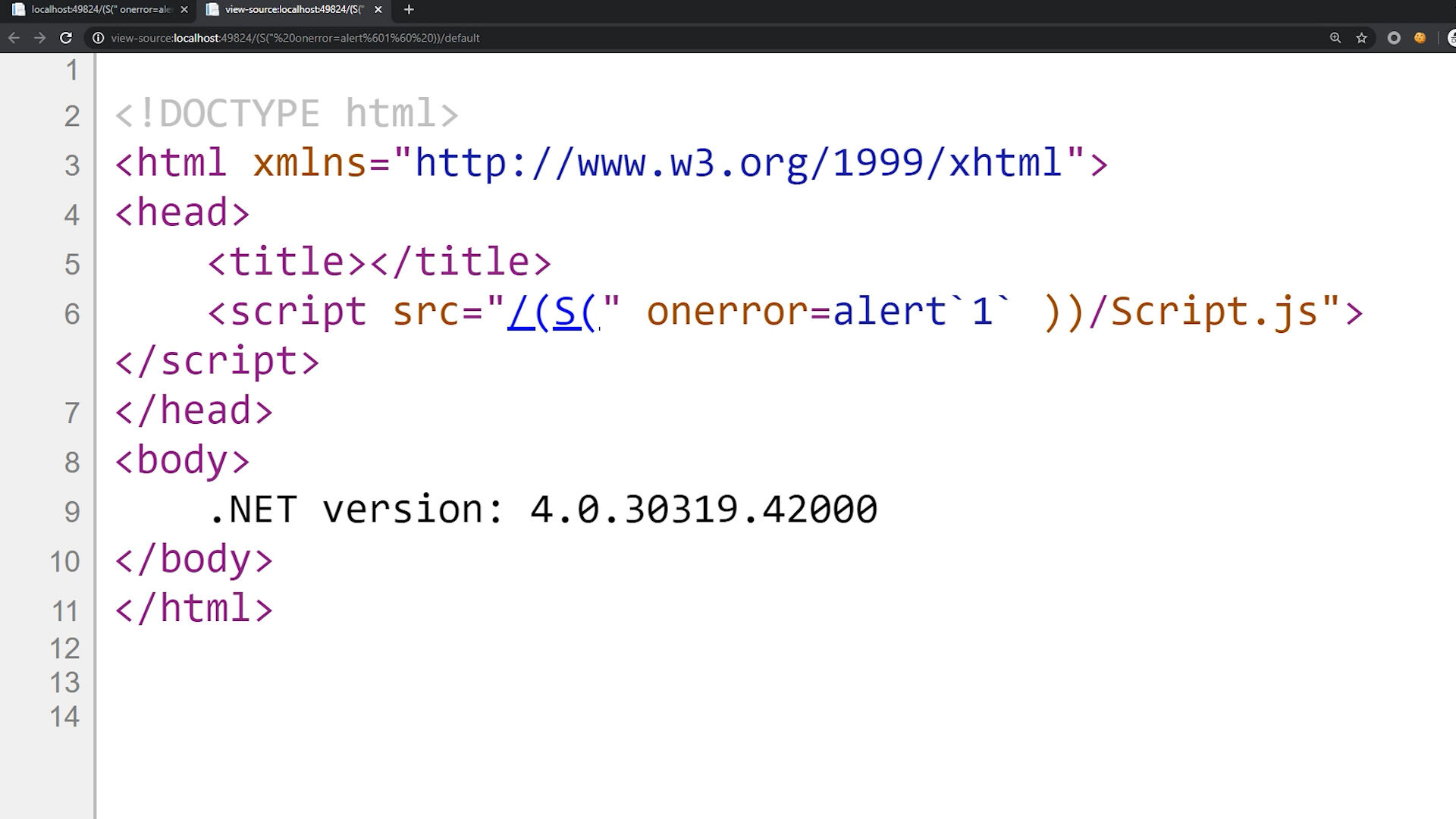
No nie do końca - wyświetliliśmy jedynie okienko z napisem 1. Wykonanie dowolnego kodu nie jest jeszcze możliwe.
Przecież złośliwy kod JS może korzystać z nawiasów, pytajników czy procentów. Musimy wymyślić metodę, która pozwala na obejście tego problemu.
Fragment a XSS
Wiemy, że nie możemy przekazywać niektórych znaków w adresie. Ale nie cały adres trafia do serwera.
Jego część - nazwana fragmentem jest widoczna jedynie z poziomu przeglądarki.
Można ją pobrać z poziomu kodu JavaScript:
document.location.hashWyświetlana wartość zawiera znak # który nas nie interesuje. Ucinamy go więc korzystając z substr, która pomija pierwszy znak:
document.location.hash.substr`1`To właśnie tam podamy cały nasz payload - czyli złośliwy kawałek kodu JS - ponieważ tam możemy używać zakazanych znaków.
W JavaScript istnieje funkcja eval - która wykonuje podany jako parametr ciąg znaków jako kod JS.
Teoretycznie więc wystarczy, że do funkcji eval podamy jako parametr document.location.hash.
Pamiętamy o naszym ograniczeniu z nawiasami - próbujemy więc skorzystać ze znaku backtick. I co? I nic.
O ile backtick działa ze stałymi wartościami - nie zadziała z wyrażeniami. Mamy tutaj do czynienia z tak zwanymi tagged templates.
Brak nawiasów jest dość generycznym problemem. Po krótkich poszukiwaniach można więc natrafić na stronę, gdzie znajduje się lista obejść tego problemu.
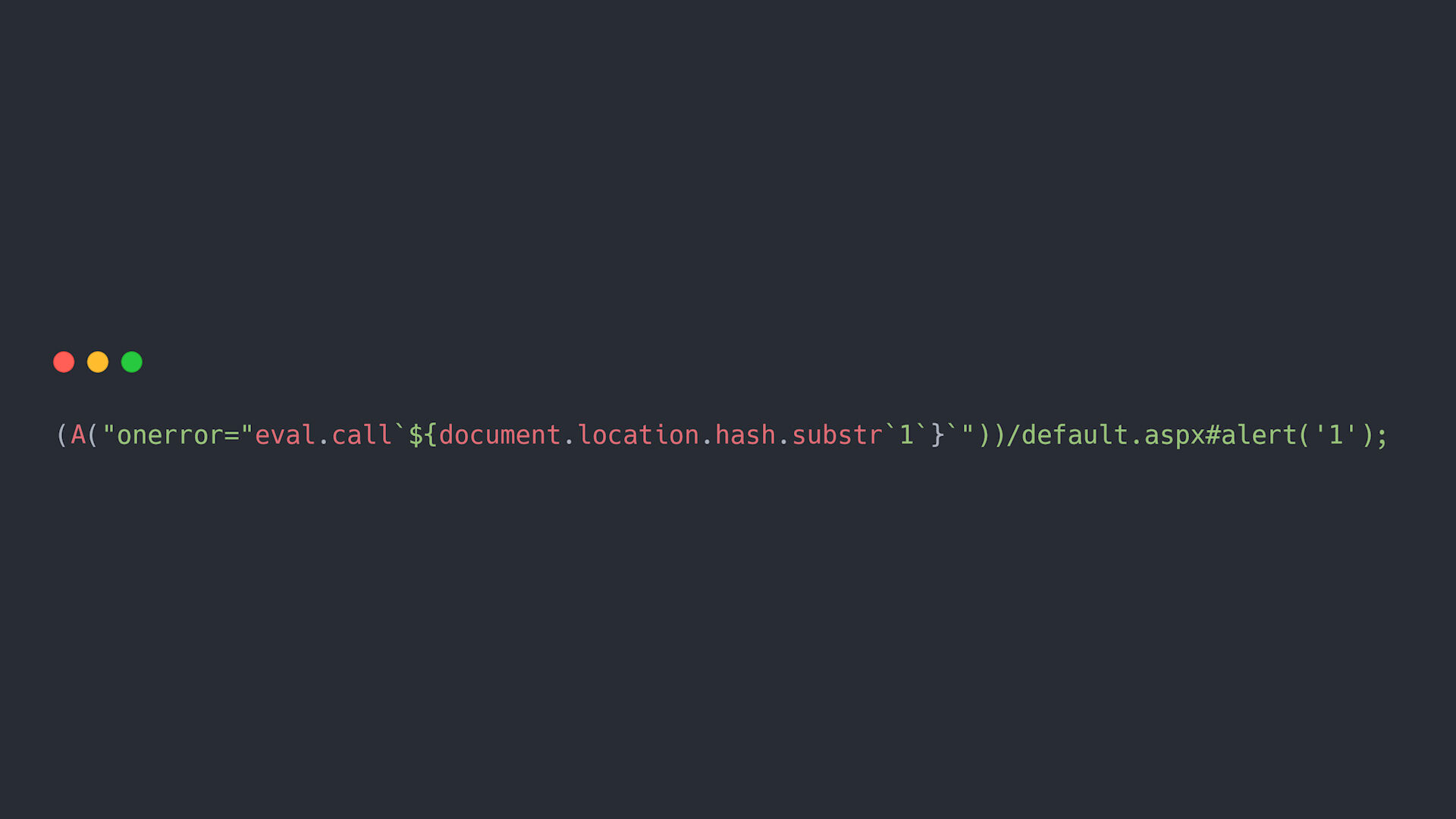
Eval.call
eval.call`${document.location.hash.substr`1`}`Widzimy tutaj, że zamiast eval - możemy skorzystać z eval.call.
Najpierw zamykamy podawanie adresu używając podwójnego cudzysłowu.
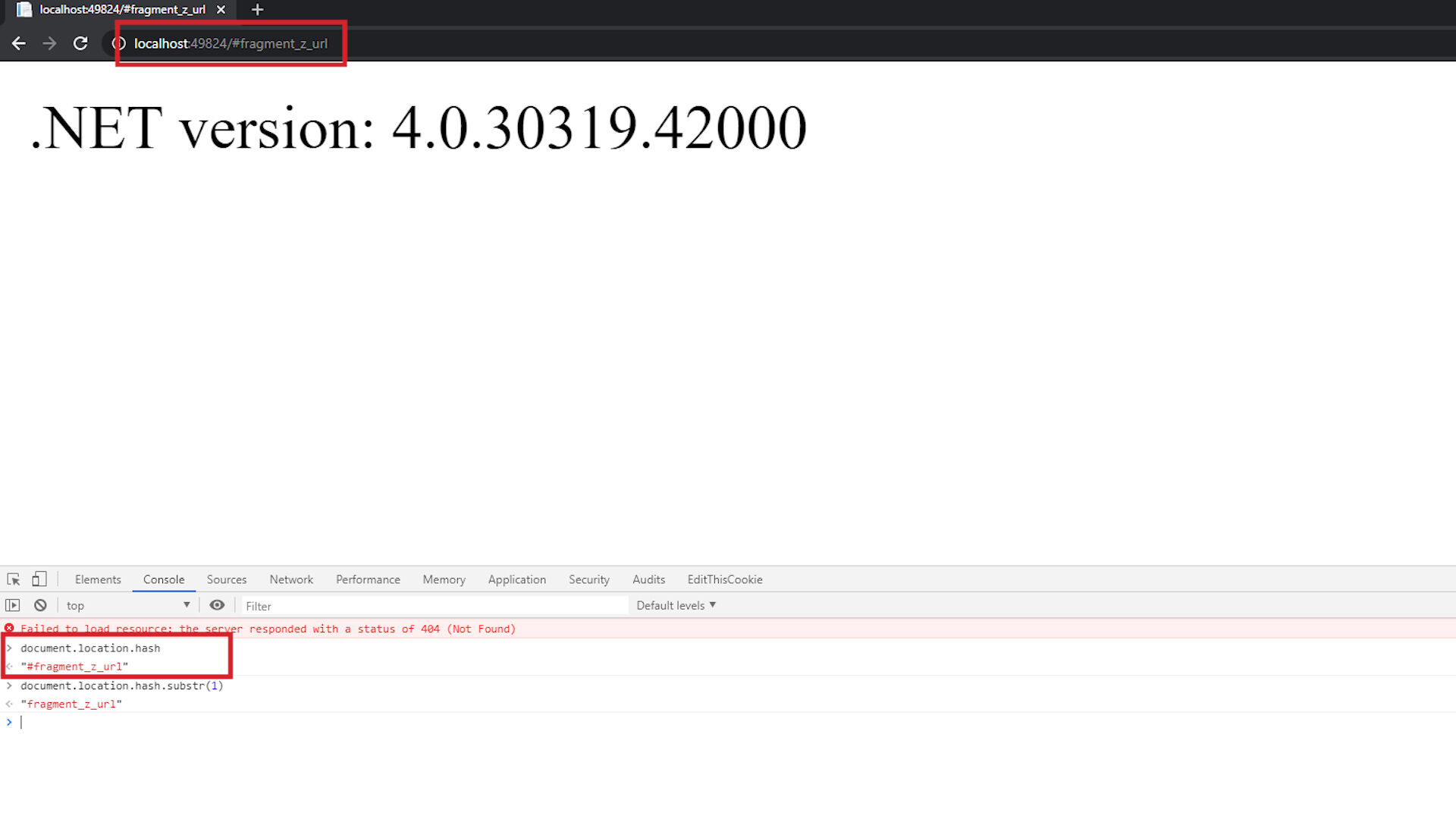
Potem tworzymy event onerror w którym za pomocą eval.call wykonujemy kod JS podany po znaku hash.
W kotwicy - czyli po znaku # znajduje się nasz kod JS - bez ograniczeń w znakach.
http://szurek.pl/aplikacja/(A("onerror="eval.call`${document.location.hash.substr`1`}`"))/home.aspx#alert('1');base64
Na koniec małe usprawnienie całej metody.
Ten atak to tak zwany Reflected XSS - czyli musimy przesłać złośliwy link do użytkownika w jakiejś formie.
Taki adres URL - zawierający wiele dziwnych nazw (czyli nasz kod JS) - może zniechęcić potencjalną ofiarę przed kliknięciem w niego.
Warto więc zamaskować jakoś potencjalny atak. Najprościej - przy użyciu base64.
Ciąg znaków można zakodować przy użyciu funkcji btoa. Jego dekodowanie odbywa się przy pomocy pokrewnej funkcji - atob.
Teraz zamiast przesyłać kod JS - skorzystamy z jego interpretacji w base64:
eval(btoa('YWxlcnQoMSk='))Ostatecznie nasz złośliwy payload wygląda następująco:
http://szurek.pl/aplikacja/(A("onerror="eval.call`${document.location.hash.substr`1`}`"))/home.aspx#eval(atob('Y29uc29sZS5sb2coJ3Rlc3QnKTthbGVydCgyKTs='));