Uwaga: to materiał z 2018 roku. Wszystkie błędy są już dawno poprawione.
Pewno większość z was kojarzy narzędzia firmy JetBrains ułatwiające programowanie. Sam nie jestem programistą, ale czasami używam tych programów do tworzenia swoich projektów.
Dowiedziałem się, że IntelliJ może przechowywać hasła do różnych serwisów (między innymi serwerów kontroli wersji, a także serwerów Continuous Integration). Jakie pytanie zadaje sobie osoba zajmująca się bezpieczeństwem? W jaki sposób te hasła są przechowywane i jak mogę się do nich dostać.

IntelliJ posiada wersję Community (której kody źródłowe dostępne są w Internecie). Po pewnym czasie wiedziałem już jak hasła przechowywane są w systemie operacyjnym. Mówiąc w skrócie:
- Główne hasło znajduje się w pliku
pdb.pw, który jest zakodowany przy pomocy Windowsowej funkcjiCryptUnprotectData. Co ona daje? Sprawia, że nawet jeśli atakujący skopiuje ten plik do swojego komputera nie będzie mógł skorzystać z tego pliku, ponieważ taki plik może być odkodowany tylko na tym samym komputerze, na którym został stworzony. - Następnie treść tego pliku była zaszyfrowana algorytmem
AESz kluczem statycznym (który można z łatwością odnaleźć w kodzie źródłowym). - Inne hasła są trzymane w formacie
KeePass(darmowego menadżera haseł). Używamy więc naszego hasła i mamy dostęp do całej bazy. - Każde hasło, które się tam znajduje jest jeszcze "xorowane" ze stałą
0xDFAA.
W ten oto prosty sposób możemy pobrać wszystkie zapisane przez dewelopera hasła znajdujące się na jego komputerze. Ale jak i po co możemy je wykorzystać?
Obecnie modny jest termin red team czyli symulacja ataku przeprowadzana przez wyspecjalizowaną do tego celu firmę.
Zacząłem sobie więc zadawać pytanie: gdybym ja miał się włamać do jakiejś firmy programistycznej, to jak bym to zrobił?
Firmy inwestują w różnego rodzaju oprogramowanie i sprzęt. Wszędzie widzimy reklamy firewalli nowej generacji i urządzeń do kontroli dostępu. Zapominamy jednak o człowieku – w naszym wypadku o programiście, który przecież codziennie pracuje i wykonuje swoją pracę.

Programowanie to praca zespołowa – gdzieś stworzony kod trzeba przechowywać – tak, aby był dostępny dla wszystkich, a także żeby łatwo można było wprowadzać do niego zmiany. Zapewne większość z was kojarzy platformę GitHub, która jest największą tego typu usługą na świecie. Drugim popularnym serwisem jest GitLab. Wcześniej znałem oba te serwisy i z obu korzystałem.
Z punktu widzenia atakującego takie serwisy są ciężkim orzechem do zgryzienia. Oba posiadają działające od dawna programy Bug Bounty i bardzo ciężko znaleźć krytyczny błąd w każdym z tych serwisów.
Ale przyglądając się tematowi bliżej odkryłem, że istnieje całe grono mniejszych projektów – będących serwerami git, które można zainstalować na swoim serwerze.
Dzisiaj pokażę swoją podróż po tych serwerach i błędy jakie w nich znalazłem.

GitList
Zaczniemy od serwera GitList – który jest napisany w PHP. Ale zanim zaczniemy poszukiwać błędów musimy zastanowić się jak można stworzyć własny serwer gita. Generalnie mamy 2 opcje.
Pierwsza – czyli skorzystanie z gotowego rozwiązania jakim jest konsolowa wersja gita. Czyli instalujemy normalnego gita – gdzie komendy można wykonywać z poziomu konsoli. Następnie tłumaczymy wszystkie akcje wykonywane przez użytkownika z poziomu interfejsu webowego na komendy w konsoli.
Tak jak na tym przykładzie – jeżeli użytkownik "commituje" jakieś pliki z poziomu interfejsu, my pod spodem wykonujemy komendę git commit z odpowiednim parametrem.

Plusy takiego rozwiązania? Jest względnie proste. Prawie każdy język programowania posiada funkcję która pozwala na przekazanie komendy do wykonania przez system.
Ale takie rozwiązanie nie jest profesjonalne. Wykonywanie jakichś funkcjonalności przy pomocy komend systemowych to bardziej domena urządzeń IOT niż dobrze napisanych projektów. Dlatego też z czasem, kiedy git uzyskał już znaczącą popularność na rynku, powstały specjalne biblioteki, które przepisywały funkcjonalność gita z języka C na inne języki programowania. Jak można się domyślić, jest to żmudny i kosztowny proces.

GitList to jedno ze starszych oprogramowań tego rodzaju, dlatego też używa tej gorszej wersji - wykorzystującej komendy gita. Tutaj przykład komendy która zostanie wykonana, jeżeli użytkownik będzie chciał wyszukać czegoś w danym repozytorium.
Czy jesteś w stanie dostrzec błąd?
Jest on bardzo subtelny i pozostał niedostrzeżony przez wiele lat. Aby go zrozumieć musimy wyjaśnić różnice pomiędzy dwoma funkcjami – escapeshellcmd oraz escapeshellarg, które są wykorzystywane w PHP.

Obie te funkcje służą do zabezpieczania parametrów przekazywanych do komendy system. W założeniu mają one chronić kod, aby atakujący nie mógł przekazać dodatkowych parametrów do naszej komendy. Zobaczmy to na przykładzie. escapeshellcmd jest zazwyczaj wykorzystywane w takiej kombinacji:

Tutaj programista zabezpiecza się przed tym, aby wykonała się dokładnie jedna komenda, która może mieć wiele argumentów. Jeżeli spróbujemy wykonać tutaj trik ze średnikiem (który w Linuxie oddziela komendy) – to on nie zadziała.

Na drugim biegunie mamy funkcję escapeshellarg która dalej pozwala na wykonanie tylko jednej komendy – ale tylko z jednym argumentem.
Jeżeli użytkownik w treści parametru pierwszego będzie próbował przemycić dodatkowy argument – to się nie uda. Jedno wykorzystanie escapeshellarg to jeden parametr.
Wróćmy więc do naszego błędu. Widzimy tutaj wykorzystanie funkcji escapeshellarg – czyli użytkownik może wykonać komendę git grep z tylko jednym argumentem. Gdzie zatem tkwi błąd?
Mówimy tutaj o jednym argumencie. Ale argument to argument. Użytkownik może wykonać dowolny argument – ale tylko jeden. Dlaczego to może być niebezpieczne?

Każda komenda może mieć wiele argumentów, które robią różne rzeczy. Git jest już na tyle popularny, że każda komenda ma wiele przełączników, które mogą być stosowane przez zaawansowanych użytkowników. Sam byłem mocno zaskoczony, kiedy po raz pierwszy zobaczyłem listę argumentów dostępnych dla komendy git grep. Istnieje tam argument –open-files-in-pager.
Jaka idea stoi za tym parametrem? Używając komendy git grep dostajemy listę plików, w których wystąpiło wyszukiwane przez nas słowo. Ale czasami możemy chcieć otworzyć te pliki w edytorze tekstu.
Zamiast więc kopiować ich ścieżki i dopiero otwierać je w notatniku – twórcy gita proponują prosty przełącznik, który pozwala nam na przekazanie nazwy edytora, który ma być uruchomiony przez gita dla pasujących plików.

Mowa tutaj o edytorze tekstu. Ale przecież git nie posiada listy wszystkich możliwych edytorów tekstu i nie sprawdza czy podany przez nas parametr jest rzeczywiście nazwą edytora tekstu czy też dowolną inną aplikacją. Bo jak by miał tego dokonać?
Spróbujmy zatem spróbować przekazać do argumentu pager komendę, która nie jest edytorem tekstu.
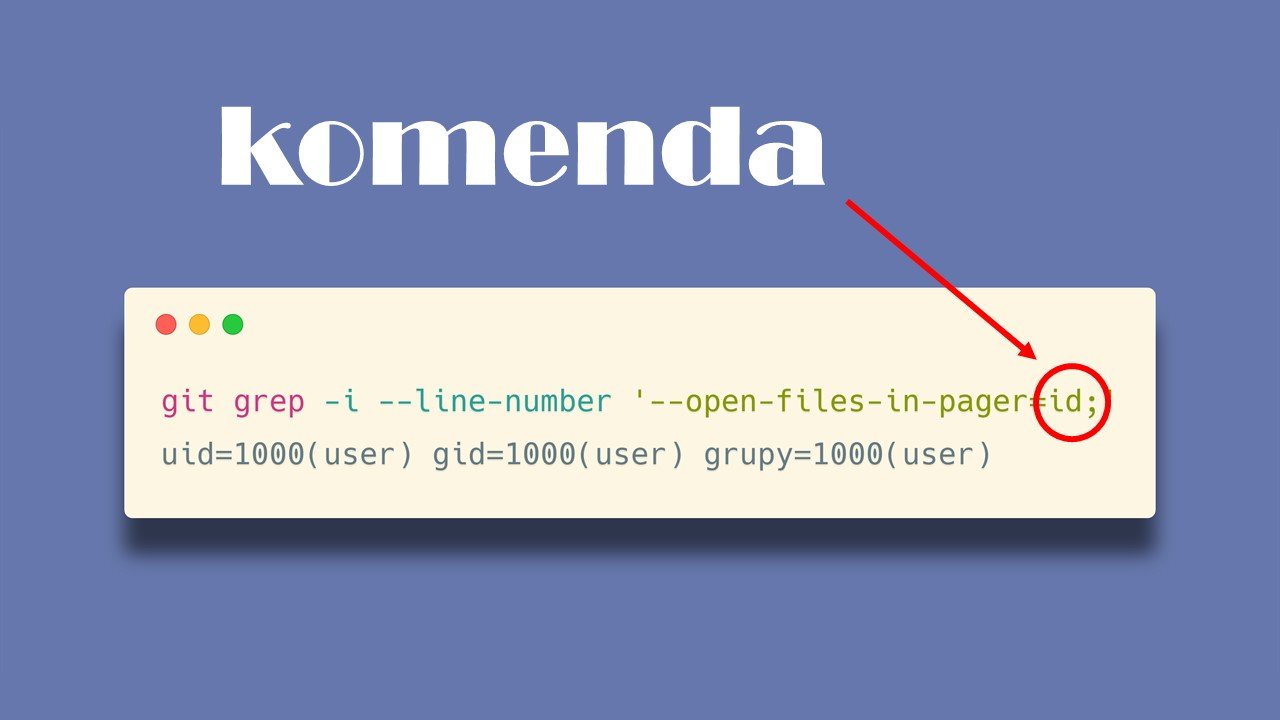
Do argumentu –open-files-in-pager przekazujemy komendę id, która wyświetla informację na temat bieżącego użytkownika..
Aplikacja używa funkcji escapeshellarg. Możemy przekazać dokładnie 1 argument – i właśnie to czynimy – przekazujemy dokładnie jeden argument.
Jaka nauka płynie z tej sytuacji?
escapeshellarg nie jest rozwiązaniem idealnym. Warto zawczasu sprawdzić, czy wykonywana przez nas komenda nie posiada argumentu, który może być nadużyty w nieprawidłowy sposób.
GitBucket
Pora na kolejny serwer – tym razem GitBucket, który jest napisany w Scali. Ale zanim przejdę do opisywania podatności, muszę wyjaśnić termin z nią związany.
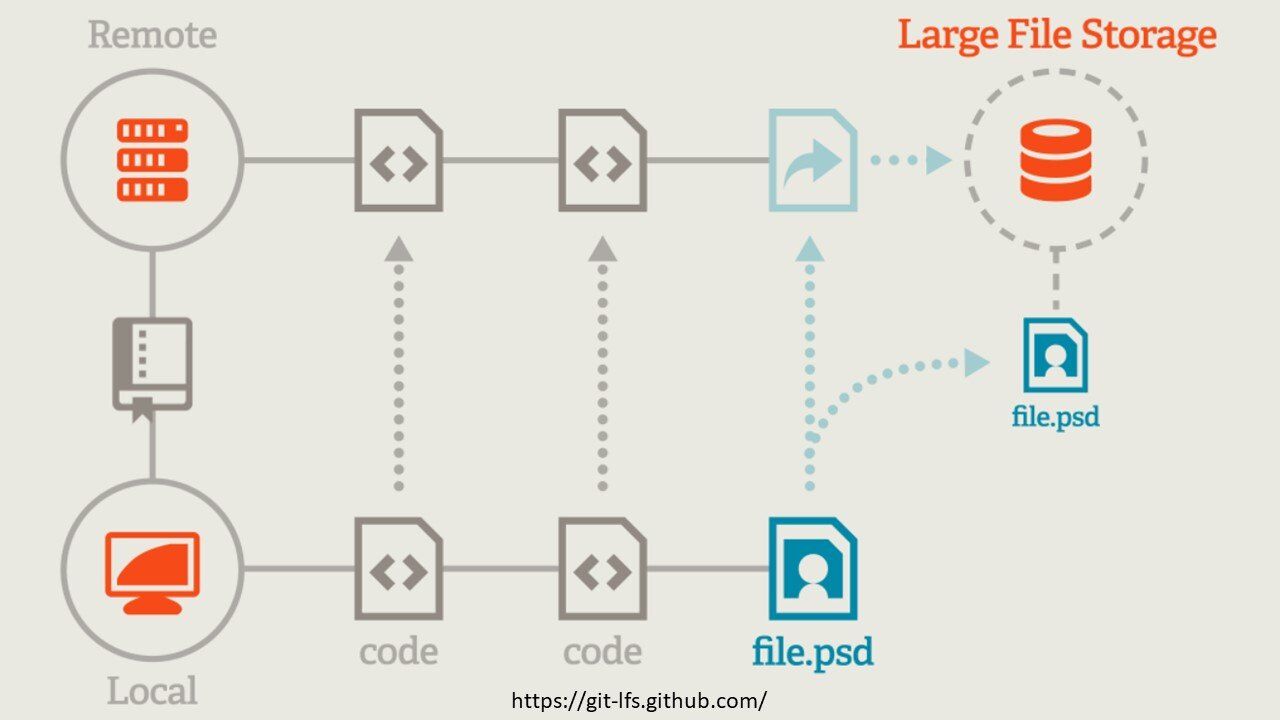
Git oprócz swoich wielu zalet posiada również wady. Jedną z takich wad jest problem z przechowywaniem dużych plików binarnych. Został on bowiem zaprojektowany do przechowywania plików tekstowych.
Klonując repozytorium, w którym znajduje się wiele plików binarnych – może dojść do sytuacji, że zajmuje ono wiele gigabajtów. Ściągamy bowiem każdą wersję wysłanego pliku. Sytuacja w której potrzebujemy każdej wersji pliku – jest rzadka. W większości potrzebujemy najnowszej wersji plików binarnych i kilka wersji wstecz.
Dlatego też powstało rozszerzenie GIT LFS. Wszystkie pliki binarne są teraz przechowywane w osobnym serwerze w oddzielnej lokalizacji. Git przechowuje jedynie informacje o tej lokalizacji. Dopiero w momencie przechodzenia na konkretny branch – git pobiera informację gdzie znajduje się plik i dopiero wtedy go pobiera. Oszczędność czasu i miejsca.
Podczas poszukiwania błędów staram się sprawdzać takie miejsca, które zostały ominięte przez innych. Zazwyczaj dobrym początkiem do analizy są nowe funkcjonalności – czyli takie, które pojawiły się w kodzie stosunkowo niedawno.
Idealnym więc przykładem był GIT LFS. Stosunkowo nowa technologia, która została dopisana do większości serwerów względnie niedawno. Tutaj widzimy kawałek kodu odpowiedzialny za pobranie parametrów definiujących jaki plik ma zwrócić serwer LFS.

Z adresu URL pobierana jest:
- nazwa użytkownika – owner,
- nazwa repozytorium,
- unikalny identyfikator obiektu - OID.
U góry widzimy adres url przekazany do użytkownika. Funkcja ta dzieli link na części rozdzielając każdą z nich przy użyciu slash.
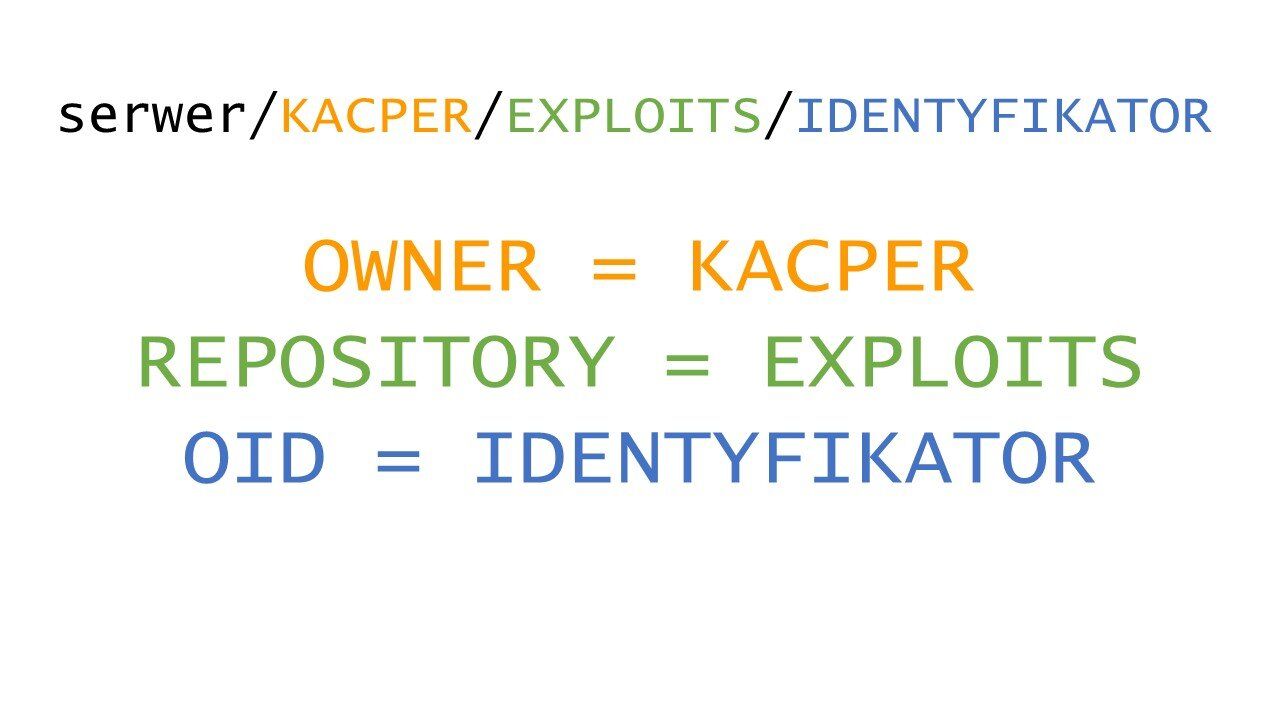
Następnie bierze ostatnie 3 elementy i przypisuje je odpowiednio do zmiennych:
- owner,
- repository,
- oid.
Następnie te dane są przesyłane do funkcji wyświetlającej odpowiedni plik. W tego typu miejscach próbujemy wykorzystać atak path traversal.

Do adresu url doklejamy więc ciąg ../
Pod Linuxem taki ciąg znaków oznacza: przejdź katalog wyżej. Jeżeli więc taki ciąg zostanie przekazany do funkcji wyświetlającej plik, to zamiast odczytać plik z prawidłowego katalogu, odczyta ona plik z katalogu nadrzędnego. A ponieważ kontrolujemy wszystkie parametry przekazywane do tej funkcji – moglibyśmy przy jej pomocy pobrać dowolny plik. Tutaj wykorzystujemy właśnie tą technikę.
Niestety, nie zadziała ona prawidłowo.
Tak jak mówiłem wcześniej, skrypt dzieli adres URL na części przy pomocy znaku / i pobiera ostatnie 3 z nich. W tym wypadku zmienna repozytorium zawiera 2 kropki.
Nam natomiast chodzi o to, aby te kropki znajdowały się w OID – które wskazują na nazwę pliku do pobrania. Skrypt przed pobraniem pliku sprawdza bowiem czy dany użytkownik i repozytorium istnieje. W tym przypadku repozytorium „dwie kropki” nie istnieje.
Dodając kolejne dwie kropki nic się nie zmienia. Nadal identyfikator pozostaje bez zmian. Tym razem to nazwa użytkownika jest równa dwóm kropkom. Skrypt znowu nie zadziała, ponieważ nie ma użytkownika z loginem ..
Czyżby atak ten był niemożliwy do przeprowadzania?
Niekoniecznie. Podczas poszukiwania błędów musimy popatrzeć na atakowany kod z innej perspektywy, takiej której nie spodziewał się programista. Linux to nie jedyny system operacyjny jaki istnieje.

Mamy jeszcze całą masę komputerów z Windowsem. Tam, aby przejść katalog wyżej używamy ciągu ..\ a nie ../
A tego programista nie przewidział. Popatrzmy na przykład.

Tutaj przed identyfikatorem podajemy ciąg ..\
Jak możemy zauważyć zmienna oid zawiera teraz ciąg podatny na path traversal. Równocześnie użytkownik i nazwa repozytorium jest prawidłowa. Używając więc takiego ciągu znaków możemy odczytać dowolny plik na serwerze.
Okazuje się również, ze identyczny kod znajduje się w funkcjonalności wysyłania plików do serwera LFS.
Możemy zatem wysłać dowolny plik w dowolne miejsce na serwerze. Nadal jednak nie możemy wykonać dowolnego kodu na podatnym serwerze.
Jak tego dokonać? Czasami warto rozglądnąć się po atakowanym oprogramowaniu.
GitBucket pozwala na rozszerzanie swoich możliwości przy pomocy pluginów, pisanych przez zewnętrznych twórców. Zazwyczaj instalowanie dodatkowych funkcjonalności jest możliwe tylko przez Administratora.
Tutaj, aby zainstalować plugin, musimy go skopiować do odpowiedniego katalogu.

Skrypt cały czas monitoruje katalog plugins. Jeśli pojawi się tam nowy plik – zostanie on automatycznie zainstalowany. Tak się dobrze składa – że my możemy wysłać dowolny plik w dowolne miejsce przy pomocy poprzedniego błędu. Możemy zatem wysłać nasze rozszerzenie do katalogu plugins.
Teraz wystarczy już tylko zobaczyć jak tworzy się przykładowe rozszerzenia do tej platformy. Na GitHubie można znaleźć prosty plugin wyświetlający tekst Hello World wraz z całą instrukcją jak go zbudować.
Teraz wystarczy już tylko odpowiednio zmodyfikować kod – tak aby móc wykonywać dowolną komendę.

Widzimy tutaj podstronę exploit, która pobiera parametr command od użytkownika. W scali jeżeli zmienna kończy się dwoma wykrzyknikami – jest ona traktowana jako komenda systemowa i wykonywana przez interpreter. Na samym końcu wyświetlamy tą zmienną i już – nasz exploit gotowy.
Teraz wystarczy:
- wysłać skompilowany plik do katalogu plugins,
- odczekać kilka chwil aż zostanie zainstalowany,
- wykonać dowolną komendę przy użyciu endpointa
exploit.
Możemy wykonywać dowolny kod na dowolnym serwerze GitBucket. Jest tylko jedno ale.
Musimy posiadać login i hasło dowolnego użytkownika. A zdobycie takich danych nie zawsze jest proste. Najlepszym rozwiązaniem byłoby znalezienie podatności, która działa bez posiadania loginu i hasła. Prześledźmy zatem kod serwera LFS nieco bliżej.

Serwer LFS nie obsługuje autoryzacji poprzez login i hasło a korzysta ze specjalnego tokenu, który jest generowany przez serwer GITa. W tym wypadku bezpieczeństwo tokenu opiera się na szyfrowaniu Blowfish.
W zakodowanym tokenie znajduje się informacja jaki plik użytkownik może pobrać oraz do kiedy token jest ważny. Dzięki temu użytkownik może pobrać tylko plik do którego uprawnienia posiada i tylko w pewnym okresie czasu.
Całe bezpieczeństwo rozwiązania opiera się zatem na bezpieczeństwie klucza, który jest używany podczas szyfrowania.
Jeżeli klucz jest krótki i znany atakującemu – może on wygenerować dowolny token z dowolnymi danymi, które będą przez serwer uznane za prawidłowe. Popatrzmy zatem jaki klucz używany jest w tej implementacji.

W tym wypadku nie musieliśmy nawet znać się na programowaniu – komentarz mówił sam za siebie.
Klucz to cztery ostatnie cyfry bieżącego czasu. W tym wypadku bieżący czas to czas, w którym serwer został uruchomiony.
4-znakowe hasło to bardzo mało, a co dopiero 4-cyfrowe hasło. Zwłaszcza, że serwer nie implementuje żadnej metody, która mogłaby ochronić nas przed atakami brute force.

Wystarczy więc, że klient spreparuje 10 000 żądań o wysłanie rozszerzenia do katalogu plugins, za każdym razem używając liczby od 0 do 9999. Gdy trafimy odpowiednie hasło – serwer zwróci odpowiedź 200 i instalacja rozszerzenia zakończy się powodzeniem.
Gitea
Nadszedł czas na trzeci serwer - Gitea. Ta podatność składa się z kilku elementów. Ponownie miejscem startowym jest implementacja serwera LFS. Tutaj zamiast szyfrowania Blowfish wykorzystano tokeny JWT. Niestety, hasło stosowane do ich zabezpieczania jest odpowiednio długie i skomplikowane - dlatego tym razem nie zadziałała metoda siłowa.
Ten exploit, tak jak i poprzedni, działa bez podawania loginu i hasła. Jak zatem tym razem udało się ominąć mechanizm logowania? Odpowiedzialny był za to ten kawałek kodu w obsłudze serwera LFS:
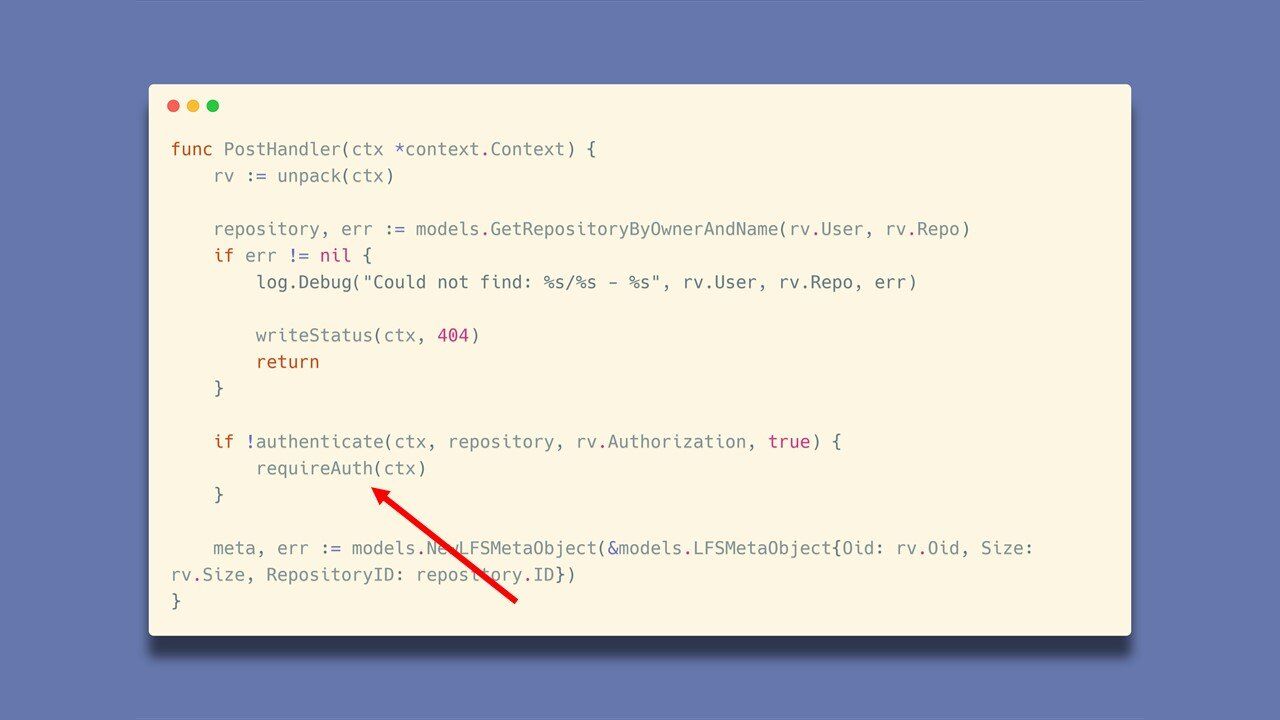
Sprawdza on czy podane przez użytkownika dane pozwalają na dostęp do danego repozytorium. Odpowiedzialna jest za to funkcja authenticate. Jeżeli użytkownik nie posiada uprawnień – funkcja requireAuth zwraca odpowiedni status błędu i funkcja kończy swoje działanie.
Ale czy aby na pewno kończy swoje działanie?

Ile osób zauważyło, że w poprzednim kodzie po wywołaniu funkcji requireAuth zabrakło słowa kluczowego return? Jedno słowo - a tak ważne. Teraz po wykonaniu funkcji requireAuth serwer wykonuje operacje dalej. Zobaczmy to na przykładzie:
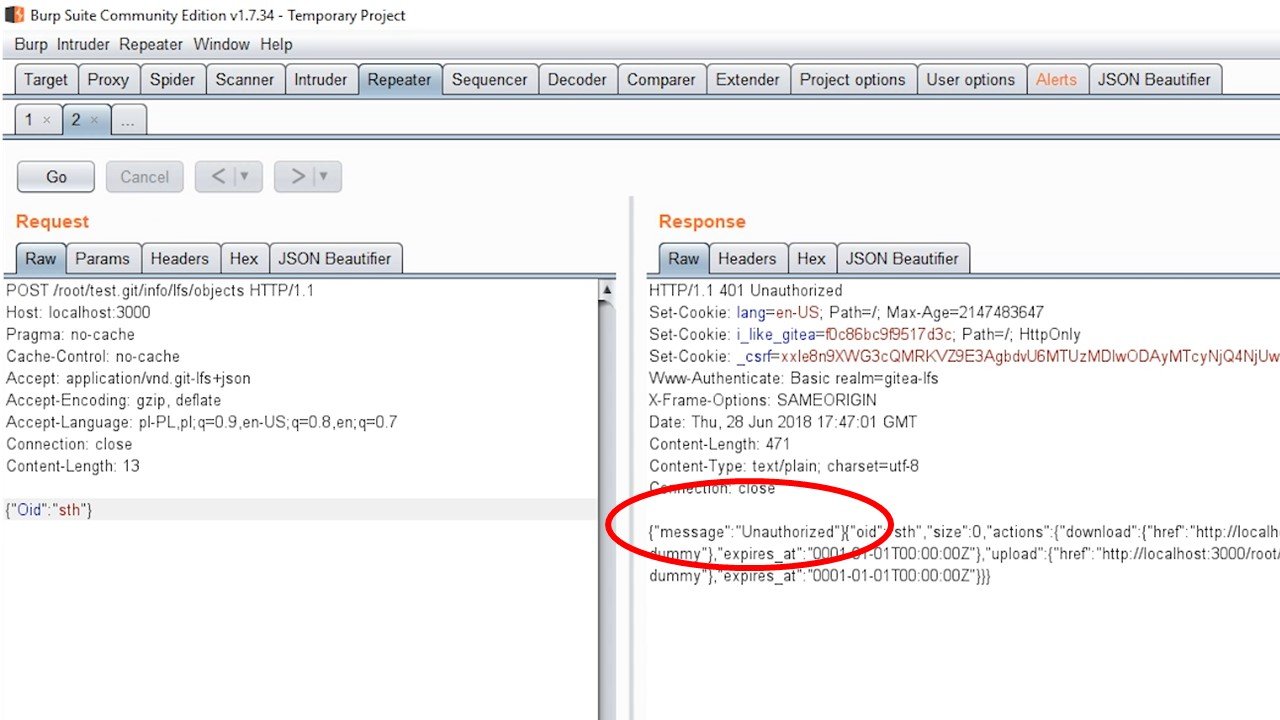
Wysyłamy przykładową wiadomość do serwera. Nie wysyłam tutaj żadnego loginu czy hasła oraz żadnego tokenu autoryzującego moją transakcję. W odpowiedzi serwer zwraca json z wartością message równą Unauthorized.
Zaraz jednak po nim zwraca kolejny json w którym informuje mnie gdzie mogę znaleźć żądany obiekt. W taki oto sposób możemy wykonywać dowolną komendę na serwerze LFS bez loginu i hasła. Co dalej? Ponownie używamy techniki path traversal.

Tym razem funkcja odpowiedzialna za zwracanie plików działa nieco inaczej:
- Bierze ona pierwsze dwa znaki
- dokleja do nich
/ - bierze następne dwa znaki
- do nich również dokleja
/ - pozostałe znaki traktuje jako resztę ścieżki
Również i tutaj zatem możemy pobrać dowolny plik z serwera. Nie możemy jednak wysłać dowolnego pliku na serwer ponieważ do wysyłki plików potrzebny jest prawidłowy token JWT.
W poprzednim przykładzie token był szyfrowany przy pomocy 4-cyfrowego hasła.
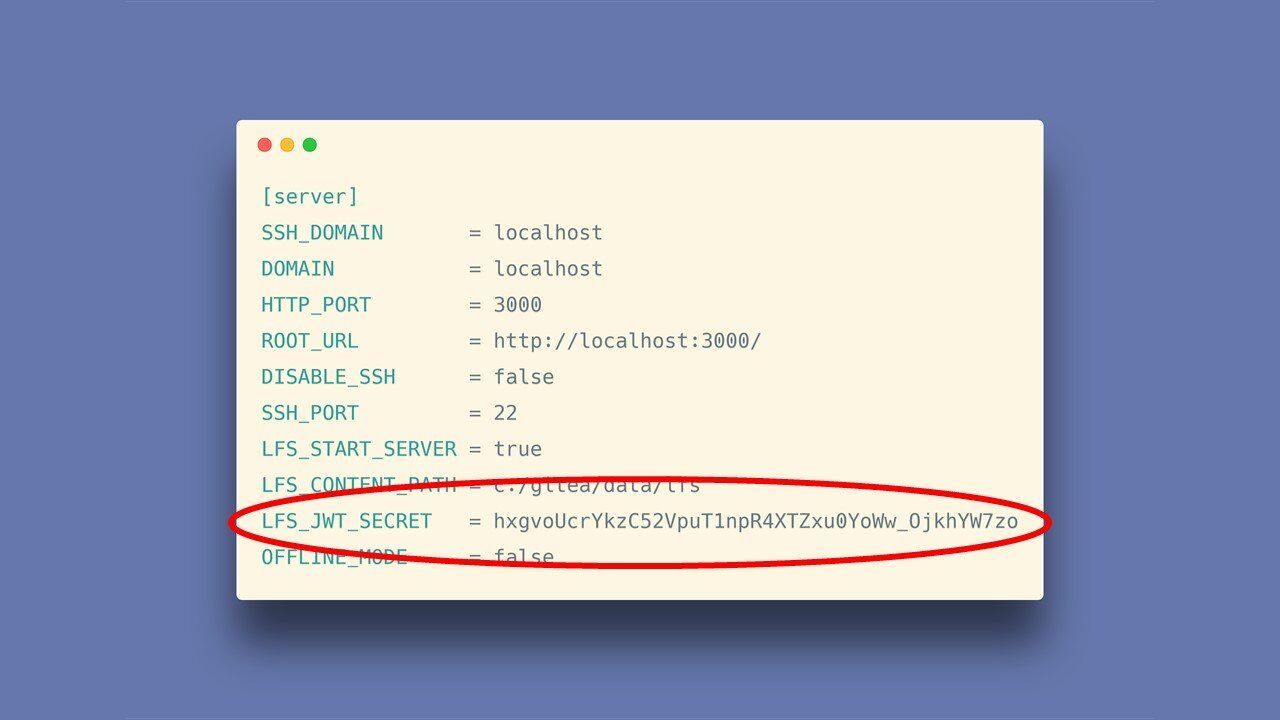
Tutaj natomiast hasło jest odpowiednio długie i skomplikowane i przechowywane w pliku konfiguracyjnym. Najpierw więc musimy pobrać ten plik używając poprzedniej podatności.
Posiadając już hasło używane do podpisywania tokenów JWT możemy stworzyć dowolny token dla dowolnej wartości. Ten token jest sprawdzany podczas wysyłania plików.
Zamieniliśmy zatem możliwość pobrania dowolnego pliku w możliwość wysłania dowolnego pliku. Pora na zdalne wykonanie kodu. Cały czas wykorzystujemy pierwszy błąd – czyli brakujące słowo kluczowe return kiedy to łączymy się z funkcjonalnością serwera LFS.
Ale jak Gitea rozpoznaje czy użytkownik jest zalogowany kiedy używamy tego serwera w prawidłowy sposób?
Po zalogowaniu użytkownikowi tworzone jest ciasteczko i_like_gitea, w którym to zawarty jest identyfikator sesji.

Standardowo Gitea do przechowywania sesji wykorzystuje pliki tekstowe. Nazwa ciasteczka to nazwa pliku z sesją. My możemy już stworzyć dowolny plik na serwerze. Może by tak stworzyć fałszywy plik sesji – tak aby serwer myślał, że jesteśmy zalogowani?
I tak próbowałem zaatakować ten serwer.
Przy użyciu poprzedniej metody wysyłałem plik na serwer i próbowałem się na niego zalogować zmieniając nazwę ciasteczka. Jakie było moje zdziwienie gdy sprawdzając wysłane na serwer pliki zauważyłem że mojej sesji tam nie ma. Ale jak to – przecież wszystko powinno działać?
Spójrzmy na kod wysyłki plików do serwera LFS:
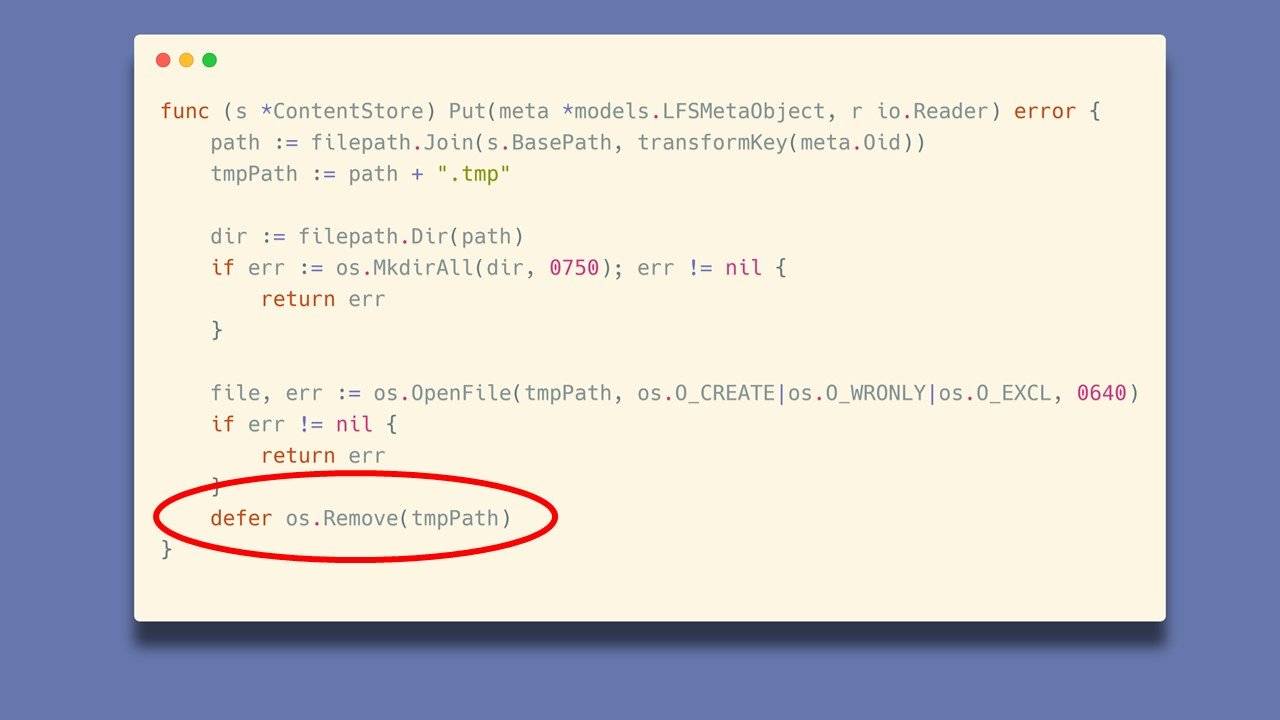
Do naszej ścieżki wyliczonej na podstawie funkcji transformKey doklejany jest ciąg .tmp na końcu i to właśnie taki plik jest zapisywany. Podczas próby mojego ataku nadal jednak taki plik nie był tworzony. Dlaczego? Pora na szybki kurs języka GO. Czy zauważyliście słowo kluczowe defer?
Defer to konstrukcja zbliżona do finally.
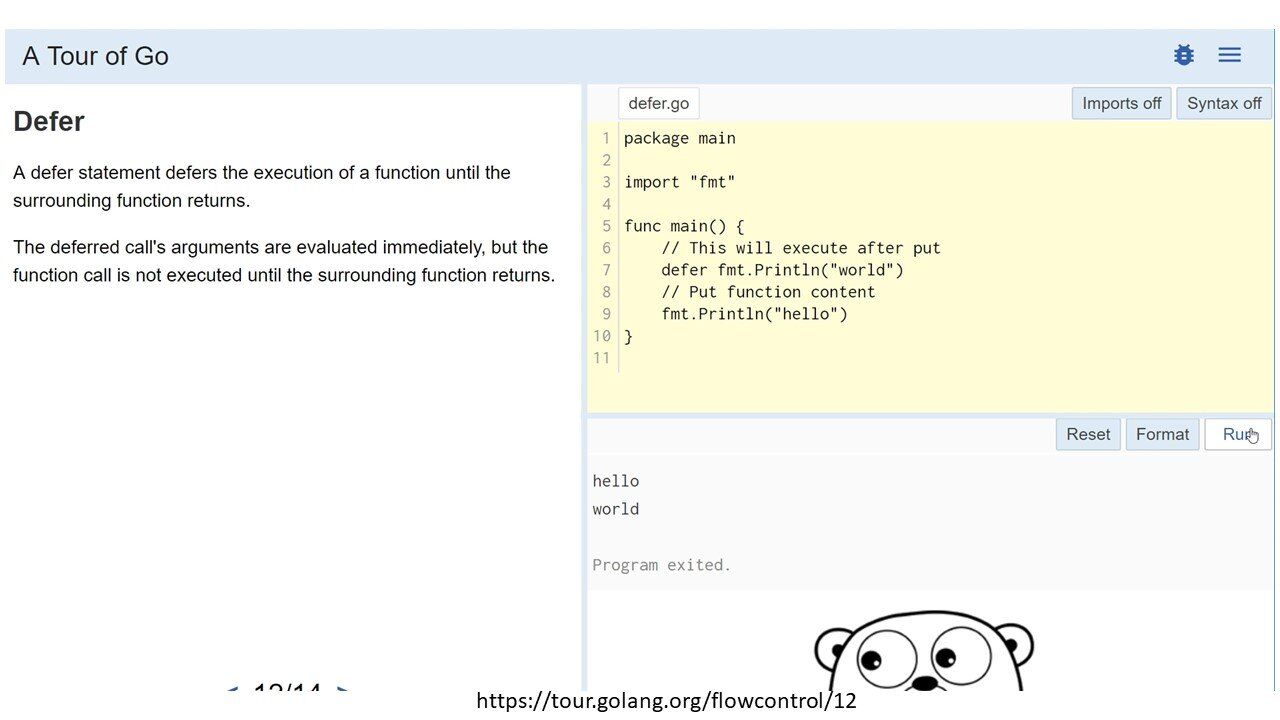
Jest to więc coś co wykona się zawsze po opuszczeniu danej funkcji. W naszym wypadku w konstrukcji defer zawarte było wywołanie funkcji remove. To dlatego mój wysłany plik nie był widoczny w miejscu którym go szukałem. Był to bowiem plik tymczasowy, który był następnie przenoszony do innego miejsca (którego ścieżka nie jest już kontrolowana przez użytkownika). Po przeniesieniu, plik tymczasowy był natomiast usuwany.
Nie miałem pomysłu jak wykorzystać tą podatność. Wykonanie funkcji trwało milisekundy. Zbawieniem okazał się atak Race Condition.
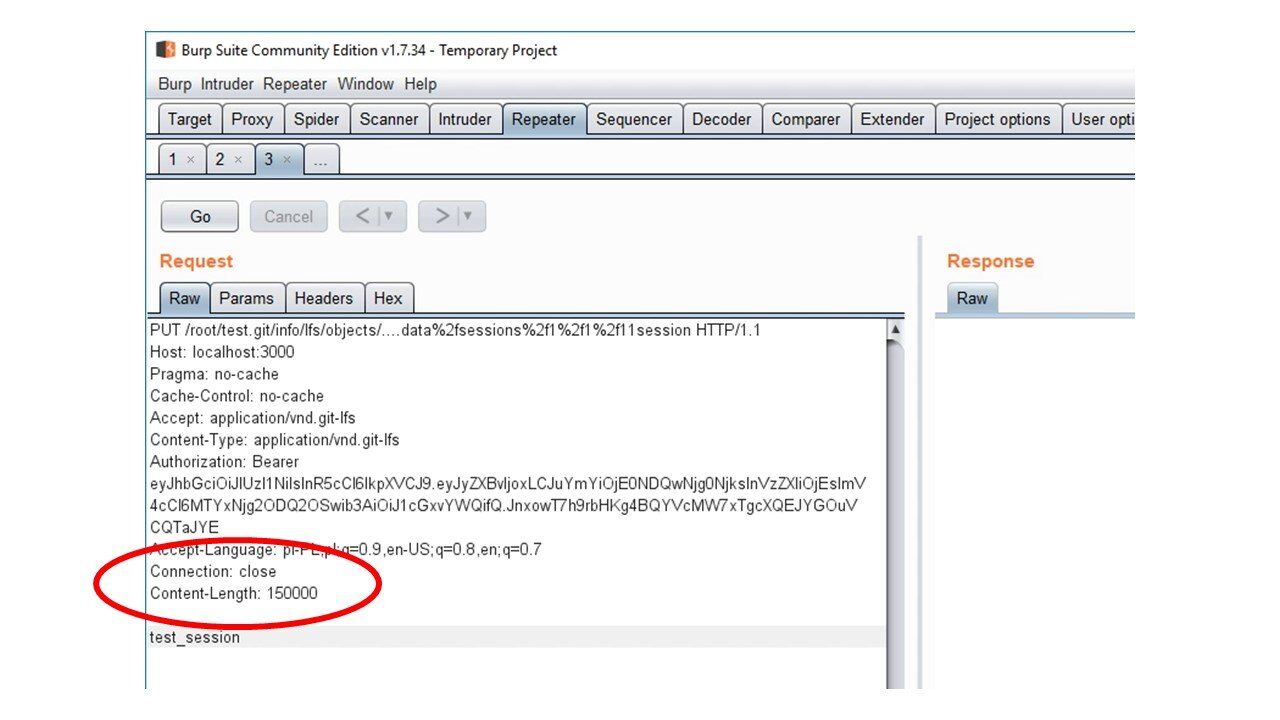
Gdy wysyłamy request do serwera przeglądarka automatycznie wypełnia za nas nagłówek Content-Length. On to informuje serwer na ile jeszcze danych musi czekać. Dla mniejszych wartości nie ma to większego znaczenia. Inaczej jest jednak gdy przesyłamy duży plik.
Ustawiając nagłówek Content-Length na dużą wartość, serwer nie wykonywał od razu konstrukcji defer. Jednocześnie treść do pliku była dopisywana na bieżąco.
W taki oto sposób otwierało się dla mnie okno czasowe w którym mogłem się zalogować. Jako iż kontrolowałem wartość pliku sesji mogłem się teraz zalogować jako dowolny użytkownik – również jako administrator. W poprzednim przykładzie wykorzystaliśmy mechanizm rozszerzeń, aby wykonać zdalny kod. Tutaj jednak nie było takiej opcji. Musiałem znaleźć coś innego.

Git posiada jednak funkcjonalność hooków. Jest to specjalnie zdefiniowany wcześniej kod, który zostanie wykonany w momencie kiedy wykonujemy jakąś akcję. Na przykład hook o nazwie update wykonuje się kiedy użytkownik wysyła coś do repozytorium wykonując komendę git push.
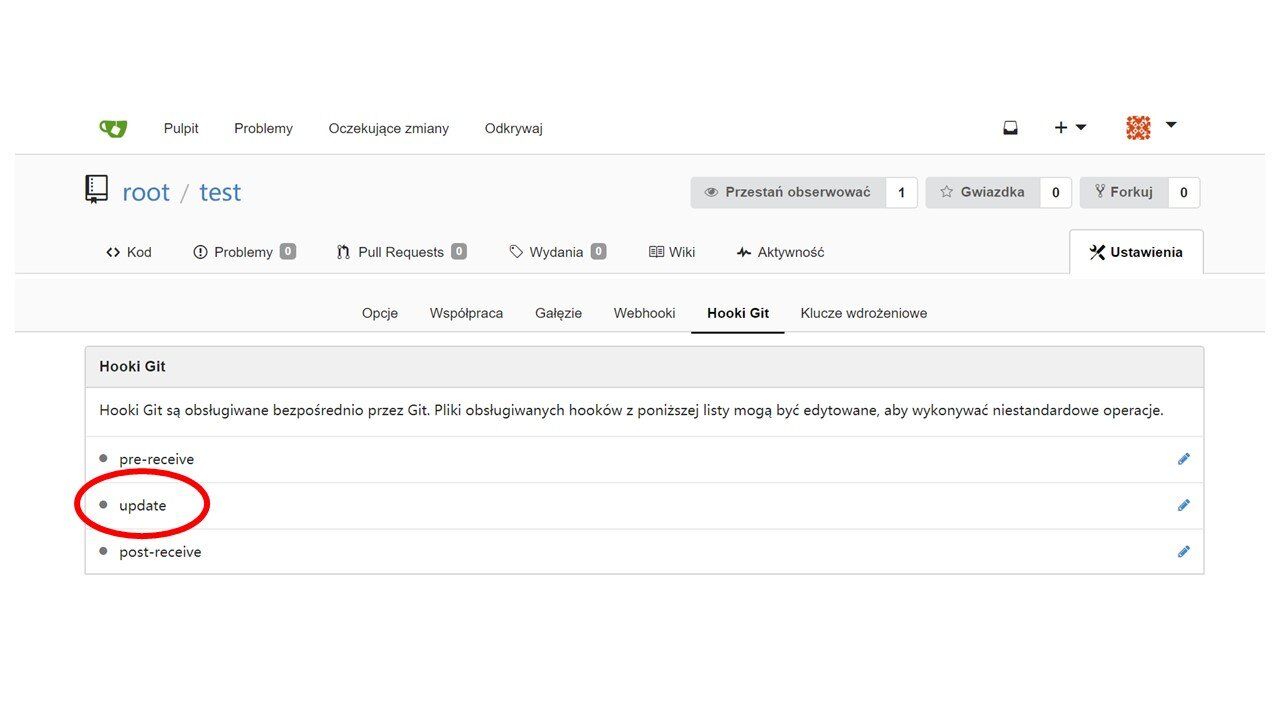
Każdy administrator Gitea mógł definiować takie hooki dla dowolnego repozytorium korzystając z odpowiedniej zakładki.
Wystarczyło więc w hooku update podać kod do wykonania a następnie:
git clone- drobna zmiana
git push
Bitbucket
Kolejny serwer to Bitbucket – jeden z najbardziej rozbudowanych oraz jedyny, który jest komercyjny oraz płatny. Tym razem nie przyglądałem się temu serwerowi a jego rozszerzeniom.
Jednym z takich rozszerzeń jest Secure Login – które pozwala na dodanie dwuskładnikowego uwierzytelnienia do tego serwera.
Po zalogowaniu się, użytkownik jest proszony o przepisanie dodatkowego kodu, który jest generowany zazwyczaj na telefonie. Dopiero po podaniu tego tokenu – możliwe jest dalsze korzystanie z tego serwera.
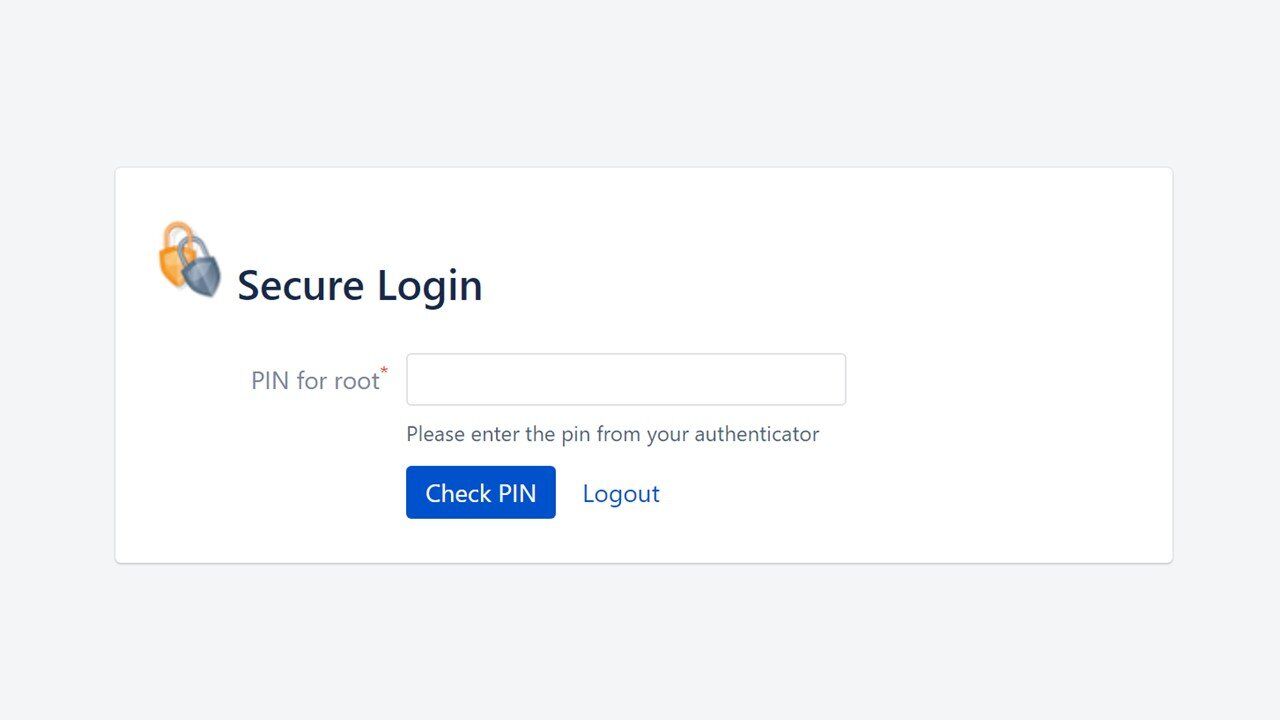
Najpierw rozszerzenie musi zostać włączone przez administratora. Podczas aktywacji widzimy listę opcji do skonfigurowania. Jednym z elementów jakie możemy kontrolować jest whitelista.
Jak czytamy w opisie do pola:
Jest to lista stron rozdzielonych przecinkiem, które nie mają być chronione dwuskładnikowym uwierzytelnieniem.
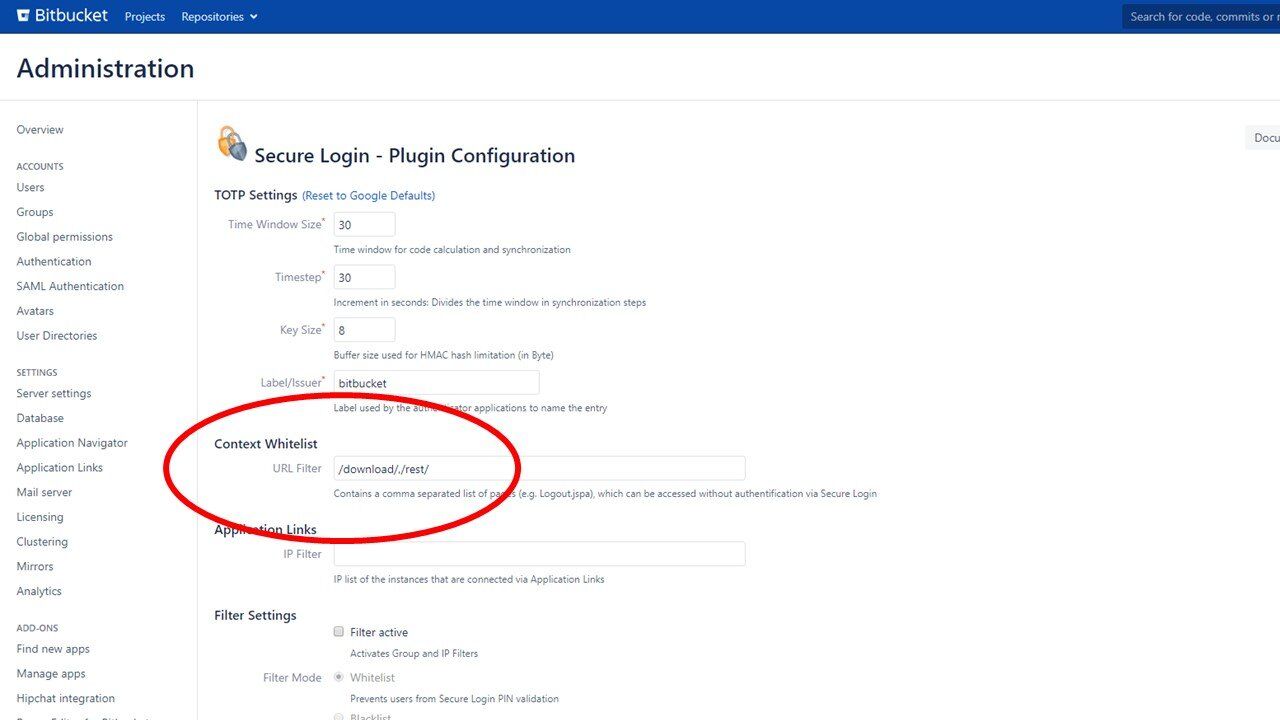
Taka opcja konfiguracyjna ma sens. Możemy chcieć aby część funkcjonalności była dostępna bez dodatkowego zabezpieczenia. Problem jednak w tym, że standardowo oprogramowanie umieszczało w tym polu 2 odnośniki:
- download
- rest
Dla tych, którzy nigdy nie mieli do czynienia z Bitbucketem – oprócz interfejsu webowego posiada on rozbudowane API. Dzięki temu możemy się z nim komunikować przy pomocy zewnętrznych skryptów w prosty i przyjazny sposób.
To API dostępne jest przy użyciu endpointa – rest.
A jak wiemy z poprzedniego slajdu – ten endpoint był wykluczony z tego zabezpieczenia. Oznacza to, że możemy korzystać z API znając jedynie login i hasło. Tak się składa, że rozszerzenie to udostępnia również swoją funkcjonalność poprzez API.
Wystarczy zatem wykonać request usuwający dwuskładnikowe uwierzytelnienie poprzez API i już możemy się zalogować przez normalny interfejs webowy.
Kallithea
Ostatni przykład jakim chciałbym się dzisiaj podzielić to serwer Kallithea.
Oprogramowanie używa języka Python. Do sprawdzania uprawnień użytkownika używa dekoratorów – czyli specjalnych ciągów znaków, które umieszcza się przed definicją funkcji.
Tutaj widzimy dekorator HasRepoPermission, który sprawdza czy użytkownik posiada uprawnienia administratora.
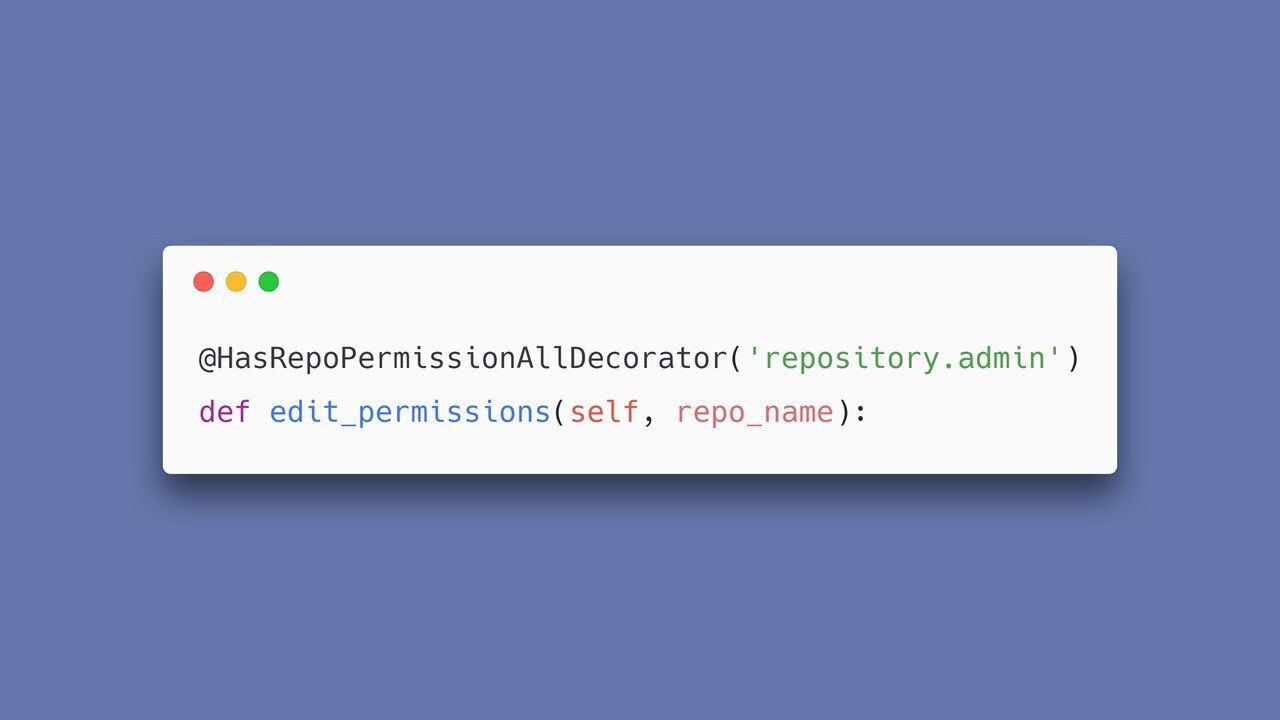
I tylko w takim wypadku może uzyskać dostęp do funkcji edit_permissions.
Gdy widzimy takie dekoratory, pierwsza rzecz jaka przychodzi na myśl – to sprawdzenie, czy ktoś gdzieś nie zapomniał o dopisaniu dekoratora do którejkolwiek z funkcji. Pech chciał, że w tym wypadku zabrakło dekoratora przy funkcji, która umożliwiała modyfikację uprawnień repozytorium.

W założeniu – mógł z niej korzystać jedynie administrator. Bez tego dekoratora jednak – dostęp do tej funkcji miał dowolny użytkownik.
Wystarczyło więc wywołać tą funkcję na interesującym nas repozytorium – i dopisać się do listy użytkowników, którzy posiadali do niego dostęp.
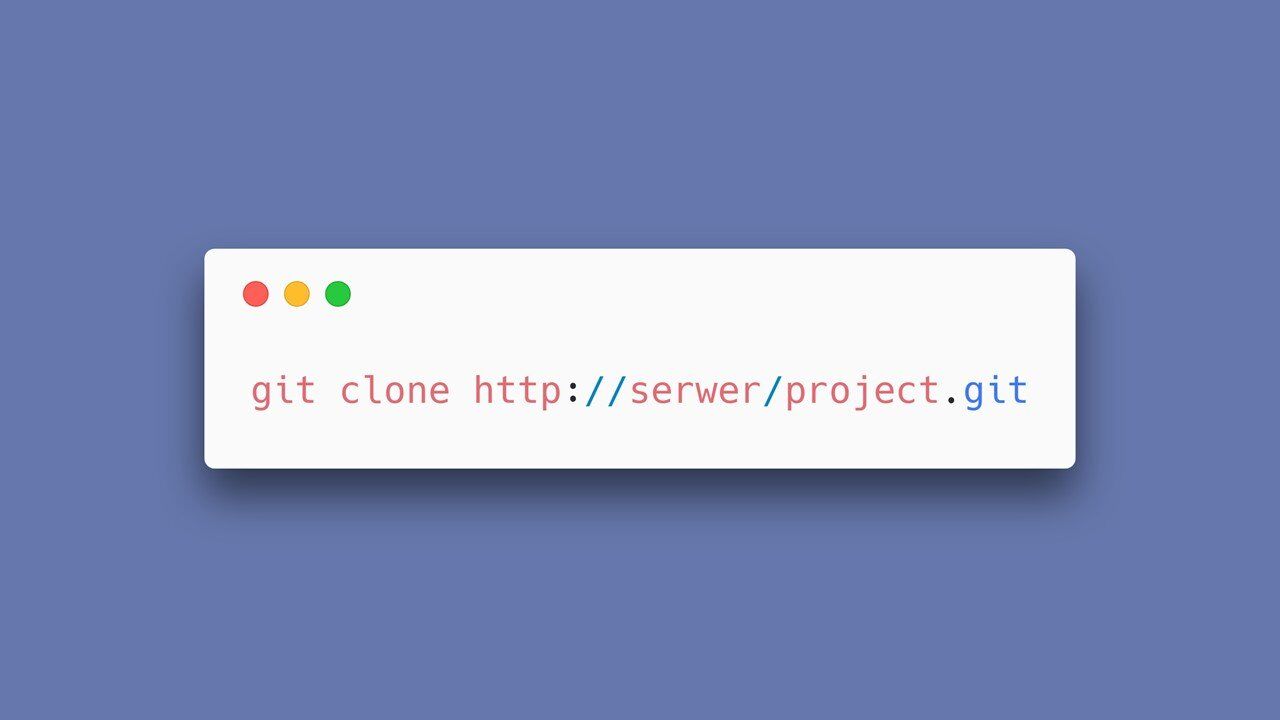
Drugi błąd wynikał z błędnej implementacji funkcjonalności klonowania. Można bowiem było stworzyć nowe repozytorium, które opierało się na jakimś innym.
Podczas tworzenia repozytorium podawaliśmy ścieżkę do bazowego repozytorium, którego treść miała zostać zaimportowana.
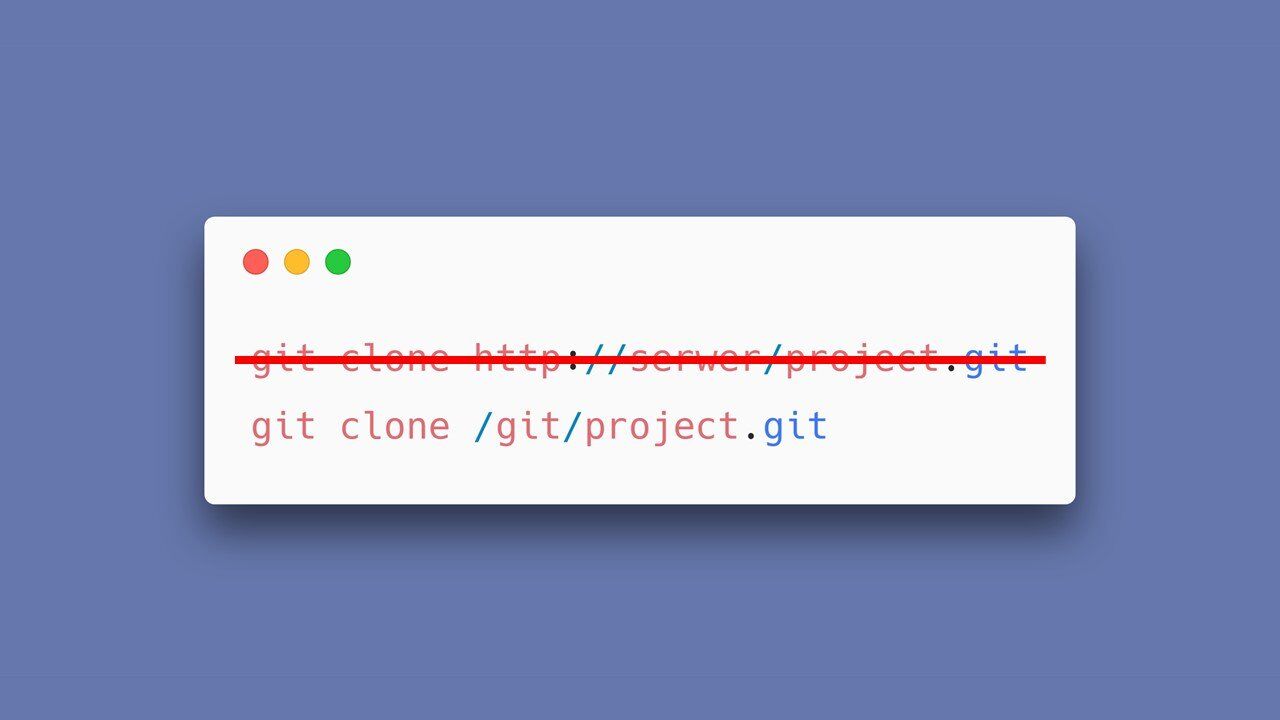
Tutaj błąd polega na tym iż git oprócz klonowania zdalnych repozytoriów (czyli takich, które znajdują się na zewnętrznych serwerach) - pozwala również na klonowanie lokalnych repozytoriów – dostępnych na lokalnym serwerze.
Jeżeli więc znaliśmy nazwę repozytorium – mogliśmy go zaimportować do naszego nowo tworzonego repozytorium – nawet jeśli nie posiadaliśmy do niego uprawnień.


