Wprowadzenie
Cześć.
Ja jestem Kacper Szurek a to 26 odcinek podcastu Szurkogadanie - o bezpieczeństwie komputerowym w prostych i zrozumiałych słowach.
Tym razem dowiesz się to co jest Google Dorks - czyli jak wyszukiwać informacje w Internecie.
Opiszę również jak naukowcom udało się złamać projekt reCaptcha oraz dlaczego konkursy typu CTF mogą być dobrym wstępem do nauki bezpieczeństwa.
Na koniec błąd w Skypie umożliwiający dostęp do zablokowanego telefonu oraz lista najdroższych wypłat gotówki w ramach programów Bug Bounty.
Podcast ten można również znaleźć na Spotify oraz Google i Apple Podcasts oraz Anchor.
Jeżeli interesujesz się branżą security lub jesteś programistą, który chciałby zadać pytanie o swój kod - zapraszam na grupę 0 do pentestera na Facebooku.
Większość wiadomości z tego odcinka odnalazłem dzięki Weekendowej Lekturze Zaufanej Trzeciej Strony.
Zapraszam do słuchania.
Co to jest Google Dorks ?
Różnego rodzaju wyszukiwarki internetowe nieustannie przeczesują otchłanie Internetu w poszukiwaniu coraz to nowszej zawartości.
Dodają przy tym do swoich ogromnych baz danych wszystkie informacje, które napotkają po drodze.
Jeżeli więc mieliśmy pecha i w momencie gdy Google Bot odwiedzał naszą stronę internetową - zwracała ona błędy - na przykład komunikat o braku połączenia z bazą danych - to również ten błąd zostanie zaindeksowany przez Google – czyli będzie widoczny z poziomu tej wyszukiwarki.
Oprócz zwykłego wyszukiwania - czyli wpisania słów kluczowych w polu wyszukiwarki - możemy korzystać z bardziej zaawansowanych funkcji.
Dla przykładu możemy poszukiwać danego słowa jedynie w adresie URL albo w tytule strony - pomijając jego występowanie w treści witryny.
Całość możemy dodatkowo filtrować poszukując specyficznych typów plików, na przykład wyszukując jedynie dokumentów pdf.
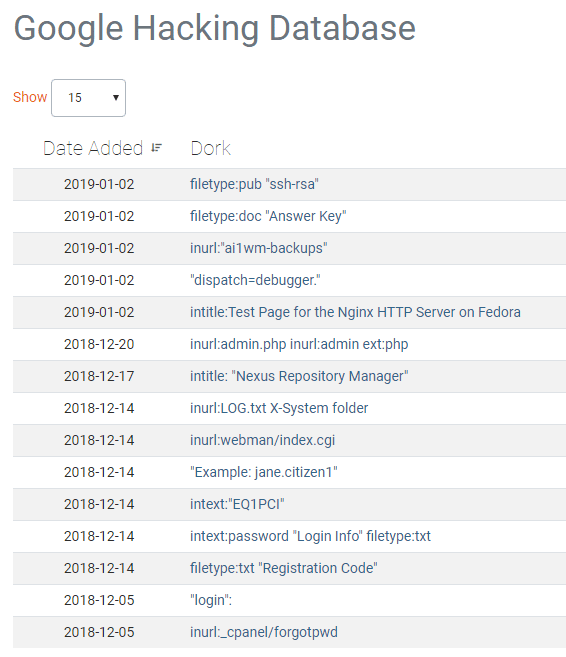
Google Dorks to gotowa baza zapytań do przeglądarek, które skonstruowane są w taki sposób aby odnaleźć pewne specyficzne dane.
Zazwyczaj służą one do odnajdowania stron, które podatne są na różnego rodzaju błędy bezpieczeństwa.
Dla przykładu, załóżmy, że pojawił się nowy błąd na konkretną wersję systemu blogowego WordPress.
W tym momencie przestępcy chcą wykorzystać tą podatność i zaatakować tak wiele systemów jak to tylko możliwe.
Mogą więc przy pomocy odpowiedniego zapytania w Google - odnaleźć wszystkie strony, w których treści znajduje się słowo kluczowe „Powered by WordPress” a następnie odpowiedni numer wersji.
W ten sposób prostym zapytaniem mogą otrzymać sporą listę potencjalnych obiektów.
Złośliwe kody QR

Policja ostrzega przed kodami QR, które można znaleźć na bankomatach.
Kod QR to zazwyczaj kwadratowy czarno-biały obrazek, zawierający w swojej treści na przykład adres strony internetowej.
Oczywiście naklejki na bankomatach nie są tam umieszczane przez właścicieli czy też banki a osoby postronne.
Mogą one kierować do różnego rodzaju stron.
Większość telefonów posiada funkcjonalność, kiedy to po zeskanowaniu kodu kreskowego używając naszego aparatu - możemy jednym kliknięciem przenieść się do strony internetowej, która się w danym kodzie znajdowała.
Jest to idealny mechanizm dla przestępców - mogą bowiem w niewinnie wyglądającej naklejce umieścić skomplikowany adres URL.
W najlepszym przypadku mogą to być fałszywe informacje o wygranej nagrodzie.
Jest to standardowy przekręt - kiedy to proszeni jesteśmy o różnego rodzaju dane.
Począwszy od miejsca zamieszkania, adresu email a skończywszy na numerze telefonu.
Numer ten może również służyć do aktywacji SMS-ów premium.
Zazwyczaj po podaniu numeru w takim formularzu otrzymujemy sms z kodem potwierdzającym.
Po jego wpisaniu na stronie usługa zostaje automatycznie aktywowana - a my będziemy co miesiąc obarczani kosztem takiego dodatkowego serwisu.
Niektóre naklejki prowadzą do witryn mających wyłudzić nasze dane do logowania do Facebooka czy też Gmaila.
W przypadku Androida - można również natrafić na takie, które będą proponowały instalację dodatkowych aplikacji - często powiązanych z bankowością elektroniczną.
Nie dajmy się nabrać i nigdy nie skanujmy takich kodów QR.
Ominięcie mechanizmu ReCaptcha
Kilka odcinków temu wspominałem, że Google wypuściło nową wersję ReCaptcha - czyli lubianego przez wszystkich projektu, który ma za zadanie wykrywać - czy użytkownik wykonujący jakąś akcję na danej stronie jest prawdziwym człowiekiem czy też maszyną.
Tym razem naukowcom udało się ominąć ten mechanizm z 91 procentową skutecznością.
Jak tego dokonali?
Okazało się to być banalnie proste.
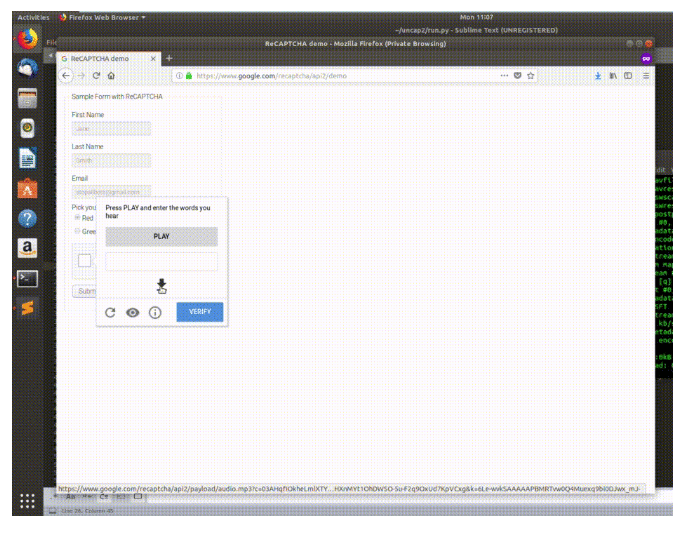
Captcha - oprócz wyświetlania obrazków posiada również swoją wersję głosową.
Wszystko po to aby osoby niewidome korzystające z Internetu również mogły z powodzeniem korzystać z tego serwisu.
W tym celu zamiast obrazków - odczytywana jest pewna fraza - którą należy przepisać.
Naukowcy pobierają ten plik audio i wysyłają go do serwisów rozpoznawających mowę.
Na chwilę obecną istnieją co najmniej trzy takie usługi - należące odpowiednio do Google, Microsoftu i IBM.
Cała więc ciężka praca związana z rozpoznawaniem mowy jest wykonywana przez firmy zewnętrzne.
Tak pozyskany wynik wkleja się do odpowiedniego pola i już - jeżeli mieliśmy szczęście właśnie ominęliśmy mechanizm obrony.
Trzeba jednak wspomnieć o jednym drobnym szczególe.
Recaptcha dość dokładnie wykrywa, czy zapytanie zostało wysłane z prawdziwej przeglądarki obsługiwanej przez człowieka przy pomocy myszki i klawiatury.
Dlatego też aby zmylić ten dodatkowy mechanizm obrony naukowcy wykorzystali bardzo prosty clicker.
Obrazek pojawia się bowiem w tym samym miejscu na danej stronie.
Wystarczy więc zaprogramować prosty skrypt aby przenosił kursor myszy w odpowiednie pole a następnie w nie klikał.
Poza tym powinien wykonywać kilka losowych ruchów - tak aby zasymulować drżenie ręki prawdziwego użytkownika.
I już. Tyle wystarczyło do złamania zabezpieczenia.
Tak proste, że aż trudno uwierzyć, że to działa.
Co to jest konkurs Capture the Flag?
Dwie polskie drużyny CTF Dragon Sector oraz p4 zajęły odpowiednio 1 i 3 miejsce w ogólnoświatowym rankingu CTFtime za rok 2018.
Jeżeli termin CTF to dla Ciebie nowość już śpieszę z wyjaśnieniami.
CTF czyli Capture the Flag to pewnego rodzaju konkursy, w których wieloosobowe drużyny - zespoły rywalizują ze sobą podczas rozwiązywania różnego rodzaju zadań związanych z bezpieczeństwem komputerowym.
Podczas każdego takiego eventu - czyli pojedynczego konkursu, do rozwiązania jest od kilku do kilkudziesięciu zadań różnego rodzaju.
Zazwyczaj są one pogrupowane ze względu na kategorię.
Dla przykładu web - w którym porusza się różnego rodzaju zagadnienia powiązane z bezpieczeństwem serwisów internetowych.
W tej kategorii możemy mieć za zadanie zaatakowanie źle chronionej bazy danych przy pomocy ataku SQL Injection czy też wykonania jakiegoś kodu Java Script na źle napisanej stronie internetowej.
Kolejna popularna kategoria to exploit - w której otrzymujemy plik binarny - zazwyczaj uruchamiający się pod Linuxem - w którym znajduje się jakaś podatność.
Naszym zadaniem jest analiza wsteczna takiego pliku i odnalezienie błędu, który się w nim znajduje.
Po zidentyfikowaniu miejsca w kodzie, które jest podatne - należy jeszcze przygotować kawałek kodu - którego zadaniem będzie takie poprowadzenie wykonania programu - które da nam pełną kontrolę nad tym co ta aplikacja robi.
Potem wystarczy już użyć takiego exploita na serwerach przygotowanych przez twórców zadania i odczytać z nich flagę.
Flaga to plik tekstowy w którym znajduje się losowy ciąg znaków zazwyczaj poprzedzony jakimś przedrostkiem.
Ten to plik jest dowodem - że udało się nam rozwiązać dane zadanie.
I to właśnie jego wpisanie na odpowiedniej stronie - daje nam odpowiednią ilość punktów.
Oprócz kategorii - zadania dzieli się także ze względu na poziom trudności.
Zazwyczaj określany ilością punktów - jakie można za nie zdobyć.
Drużyna z największa ilością punktów - wygrywa dany konkurs.
Polacy wygrali jednak cały sezon.
Co to oznacza?
Każdy CTF organizowany jest przez różne drużyny z całego globu.
Każdy z nich ma również swoją rangę - wagę. Im konkurs bardziej prestiżowy i tym samym trudniejszy - tym więcej punktów można za niego uzyskać.
To oznacza że pierwsze miejsce na słabym konkursie oraz pierwsze miejsce w renomowanym - przynosi różną liczbę punktów.
Ostateczny wynik za rok to 10 najlepszych wyników danej drużyny.
Jeżeli nigdy nie interesowałeś się tematem CTF powinieneś jak najszybciej nadrobić zaległości.
Najpopularniejszym serwisem związanym z tym tematem jest ctftime.
Znajdziesz tam listę wszystkich planowanych i archiwalnych konkursów.
Z punktu widzenia nauki - warto spojrzeć na zakładkę Writeups.
Tam to drużyny, po zakończeniu rywalizacji publikują swoje rozwiązania zadań.
To świetny pomysł aby zobaczyć jak najlepsi rozwiązują skomplikowane zagadki i jaki jest ich tok myślenia.
Dziwne czcionki a strony phishingowe

Phishing - czyli podszywanie się pod kogoś lub coś w celu uzyskania jakichś korzyści majątkowych - to popularny schemat oszustwa.
Zazwyczaj otrzymujemy wiadomość email z linkiem, gdzie informuje się nas, że ze względów bezpieczeństwa musimy zmienić hasło na którymś z popularnych serwisów internetowych.
Następnie wystarczy tylko wypełnić odpowiedni formularz na spreparowanej stronie i nasze dane do logowania trafiają w ręce przestępców.
Jednym z mechanizmów wykrywania tego rodzaju stron jest poszukiwanie słów kluczowych.
Rozpatrzmy to na przykładzie banku XY.
Wiemy, jaka jest prawidłowa domena tego banku.
Jeżeli więc na innej stronie odnajdziemy słowa kluczowe powiązane z tym bankiem - istnieje wysokie prawdopodobieństwo, że może to być strona phishingowa.
Wiedzą o tym również przestępcy dlatego starają się używać wszelakich metod aby ich strona jak najdłużej pozostawała nie wykryta.
Najnowszy wektor ataku to wykorzystanie nietypowych czcionek.
Nowoczesne przeglądarki bowiem pozwalają na używanie własnych krojów czcionek.
Aby z nich korzystać wystarczy w kaskadowych arkuszach stylów podać ścieżkę do odpowiedniego pliku woff2.
W tym to pliku definiuje się wszystkie litery w kolejności alfabetycznej - przez co przeglądarka wie, że pierwsza litera to a druga to b i tak dalej.
Trik użyty tutaj to zmiana kolejności liter w odpowiednio spreparowanej czcionce.
Pierwszą literą może być bowiem z drugą g i tak dalej.
Dzięki temu treść w kodzie strony może na pierwszy rzut oka wyglądać bardzo nietypowo - jako zlepek nieistniejących słów.
Przeglądarka jednak do ich wyświetlania wykorzystuje czcionki - a ponieważ tam kolejność poprzestawianych liter jest odpowiednia - końcowy użytkownik widzi prawidłowe zdania i wyrazy.
Trzeba przyznać, że to bardzo ciekawa technika obfuskacji - przypominająca nieco bardziej zaawansowany szyfr podstawieniowy.
Atak pass the cookie
Czy słyszałeś o ataku pass the cookie?
Jeżeli interesujesz się bezpieczeństwem to na pewno korzystasz z dwuskładnikowego uwierzytelnienia.
Dzięki niemu nawet jeżeli ktoś pozna twój login i hasło nie będzie mógł się zalogować na twoje konto.
A co gdybym Ci powiedział, że nie zawsze atakujący musi posiadać dostęp do tokenu aby używać Twojego konta?
Istnieją serwisy na których jesteśmy praktycznie zawsze zalogowani.
Myślę, że dobrym przykładem może być tutaj Facebook.
Jeżeli bowiem korzystamy z niego z naszego domowego komputera, którego jesteśmy jedynymi użytkownikami - po co mielibyśmy się za każdym razem logować do tego serwisu.
Dlatego też często zaznaczamy malutki checbkox obok pola informującego, aby strona nie wylogowywała nas automatycznie po określonym czasie.
I tu właśnie tkwi potencjalny wektor ataku.
Jak bowiem działa mechanizm logowania?
Strona sprawdza nasze dane i hasło a następnie weryfikuje dwuskładnikowe uwierzytelnienie.
Jeżeli wszystko się zgadza - zwraca do naszej przeglądarki odpowiednie ciasteczko.
Od tego momentu - za każdym razem gdy wykonujemy na serwisie jakąś akcję, to nie podajemy już naszego hasła - a to ciasteczko.
I to właśnie na jego podstawie strona weryfikuje naszą tożsamość.
Atak wygląda zatem następująco.
Przestępca uzyskuje nieautoryzowany dostęp do naszego komputera.
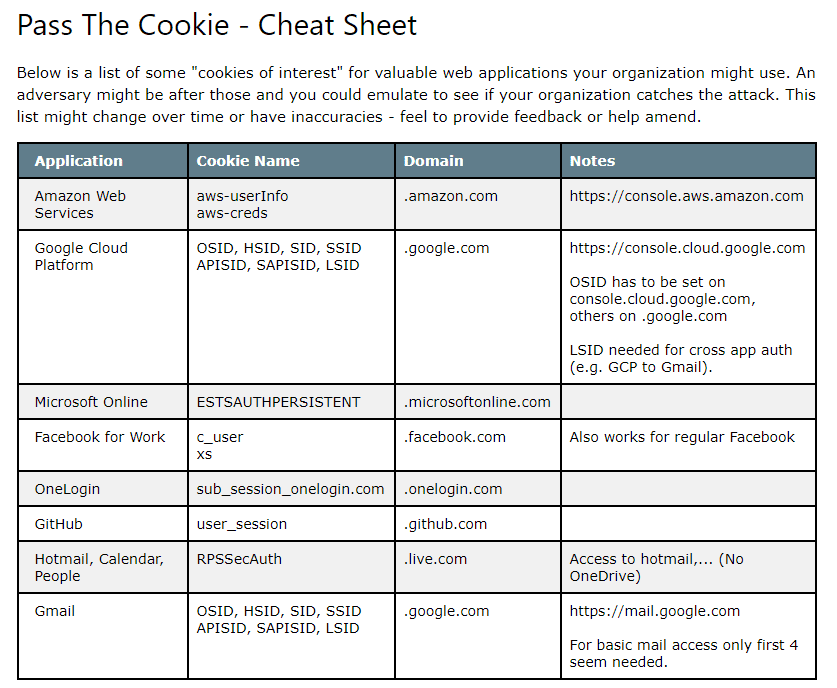
Nadal nie zna naszych danych do logowania. Sprawdza jednak pamięć podręczną przeglądarek w poszukiwaniu odpowiednich ciasteczek.
Mają one względnie unikalne nazwy co upraszcza ich odnalezienie.
Ciasteczko do usług Amazona posiada dla przykładu nazwę ws-userinfo a ciasteczko do Facebooka c_user.
Następnie atakujący kopiuje treść tego ciasteczka na swój komputer i ustawia jego wartość w swojej przeglądarce.
Jeżeli strona nie sprawdza adresu IP użytkownika – przestępca właśnie zalogował się na nasze konto bez znajomości naszych danych jak również omijając dodatkowy mechanizm weryfikacyjny.
Jak zatem ochronić się przed tym atakiem?
Za każdym razem używać przycisku „Wyloguj” w serwisach, które są kluczowe dla naszego bezpieczeństwa.
I nie wystarczy tutaj samo usunięcie ciasteczka - ważne jest aby to ciasteczko zostało unieważnione również po stronie serwera.
Free and Open Source Software Audit project
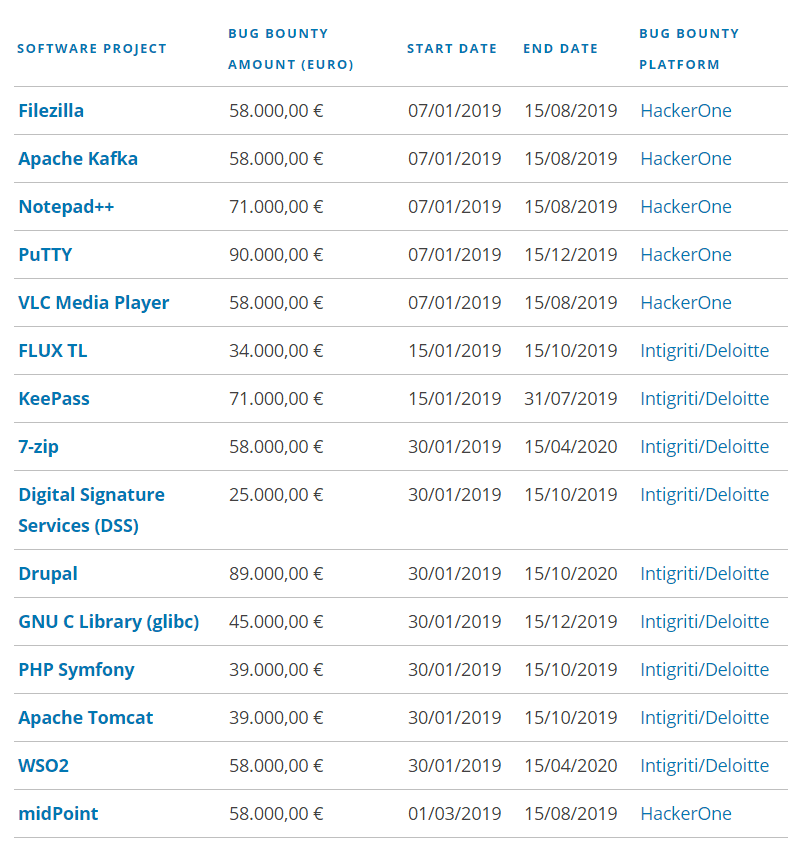
Unia Europejska w ramach FOSSA - czyli Free and Open Source Software Audit project, rozpoczęła właśnie program Bug Bounty, którego celem jest poprawa bezpieczeństwa oprogramowania typu opensource.
Programem objęto kilkanaście różnego rodzaju projektów.
Na liście znajduje się między innymi Filezilla - czyli klient FTP, Notepad++ - czyli zaawansowany edytor tekstu, PuTTY będący klientem SSH jak również Keepass - darmowy menadżer haseł a także frameworki PHP Symfony czy też system CMS dla stron internetowych - Drupal.
Cały program ma trwać około roku a całkowita kwota przeznaczona na wypłatę nagród dla osób, poszukujących błędów wynosi prawie milion Euro.
To krok w dobrą stronę. Kilka odcinków temu opowiadałem, jak Pentagon już od kilku lat z ogromnymi sukcesami przeprowadza podobne akcje w ramach zabezpieczania swoich systemów internetowych.
Spora część obecnie używanych systemów opiera się na różnego rodzaju wolnym oprogramowaniu. Warto zadbać o ich bezpieczeństwo.
Tylko, że obecnie nagradza się jedynie osoby znajdujące błędy.
Ciekawe kiedy dojdziemy do momentu, w którym pieniądze znajdą się również dla tych - którzy te błędy poprawiają w kodzie źródłowym aplikacji.
Ich praca bowiem jest równie cenna i potrzebna.
Dostęp do telefonu bez posiadania kodu PIN
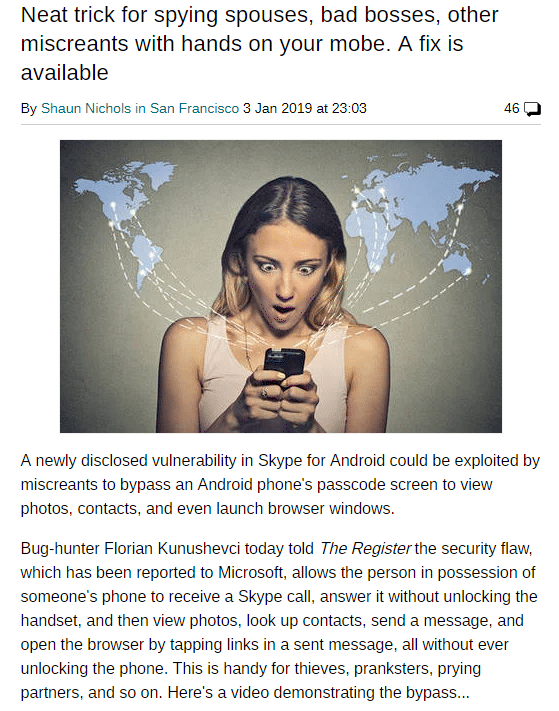
Aplikacja Skype na Androida zaliczyła mała wpadkę.
Jeżeli nasz telefon jest zablokowany kodem pin lub hasłem - aby przeglądać jego treść musimy albo odblokować go odpowiednim kodem, palcem lub też twarzą - w zależności od modelu, jakiego akurat używamy.
To ma zabezpieczać nas na wypadek kradzieży - kiedy to bez odblokowania nikt nie może uzyskać dostępu do naszych danych.
Zazwyczaj jedynym wyjątkiem jest możliwość odbierania połączeń telefonicznych - tutaj nie potrzebujemy żadnego kodu - wystarczy jedynie odebrać połączenie.
Ale też podczas przeprowadzania takiej rozmowy - nie mamy dostępu do innych treści na urządzeniu.
I tutaj w grę wchodzi błąd w komunikatorze Skype - który to pozwalał na dostęp do swojej aplikacji w trakcie rozmowy.
Jeżeli więc natrafiliśmy na zablokowany telefon - wystarczyło zadzwonić na numer skype danego użytkownika - a wtedy to mogliśmy uzyskać nieautoryzowany dostęp do zdjęć i kontaktów wprost z aplikacji.
Teoretycznie nie powinniśmy móc uruchomić innej aplikacji.
Tylko że wysyłając do kogoś link - poprzez wbudowany czat - tworzony jest automatyczny odnośnik.
A po kliknięciu - otwiera się przeglądarka.
Tym samym uzyskujemy dostęp do kolejnej aplikacji - bez posiadania hasła do telefonu.
10 największych wypłat w ramach Bug Bounty

Opublikowano listę 10 największych wypłat za odnalezione błędy bezpieczeństwa w ramach programów Bug Bounty.
Jesteś ciekaw ile można na tym zarobić?
Lista rozpoczyna się od firmy Shopify - będącej Kanadyjską platformą e-commerce, umożliwiającą szybkie stworzenie swojego internetowego sklepu.
Błąd kosztujący nieco ponad 15 000 $ pozwalał na przejęcie dostępu nad dowolnym kontem w sklepie.
Dalej Steam i błąd, który pozwalał na wygenerowanie kodów aktywacyjnych do dowolnej gry.
Jako przykład użycia, badacz wygenerował 36 000 kluczy do gry Portal 2 których rynkowa cena wynosi około 400 000 dolarów.
Za zgłoszenie tej podatności otrzymał 20 000 $.
100 tysięcy zielonych zapłacił Intel - producent procesorów za odnalezienie nowych wariantów luki Spectre.
Niewiele wyższą kwotę zaoferował Google za parę błędów pozwalających na wykonanie kodu w telefonach Pixel.
Te liczby robią wrażenie.
Spory wyciek danych w Niemczech
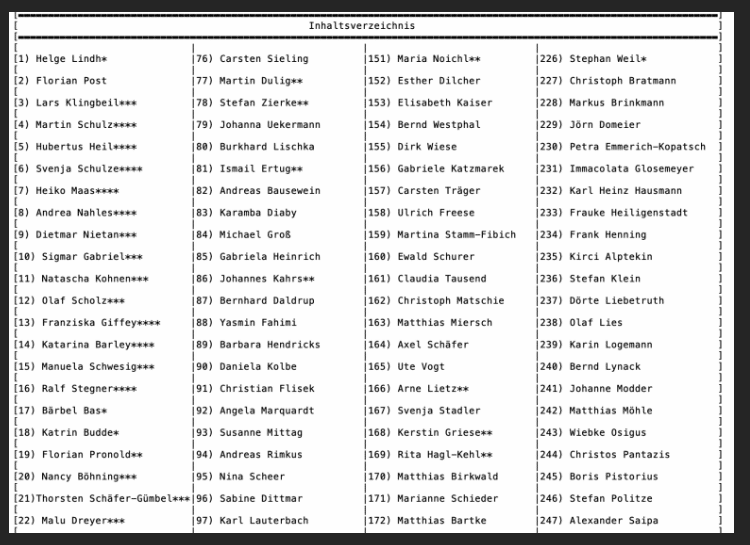
W Niemczech doszło do jednego z większych wycieków danych w historii.
W Internecie można odnaleźć dane na temat około 1000 niemieckich polityków.
Dane są bardzo dobrze posegregowane i uporządkowane - co dziwi.
Przygotowanie i przejrzenie materiałów w tej skali musiało kosztować sporo czasu.
Wśród wykradzionych danych znajdują się między innymi prywatne numery telefonów i adresy email oraz treści wiadomości.
Skany dokumentów jak również zapisy rozmów z komunikatorów a także różnego rodzaju zdjęcia.
Oprócz polityków wyciekły również dane dziennikarzy i artystów oraz youtuberów.
Nasuwa się zatem pytanie jaki cel mieli atakujący i jak długo zajął im atak.
Ze wstępnych ustaleń wynika bowiem, że dane pochodzą z różnych miejsc i serwerów oraz serwisów.
I to wszystko w tym tygodniu.
Zapraszam do dołączenia do grupy od 0 do pentestera na Facebooku i subskrypcji kanału KacperSzurek na YouTube.
Do zobaczenia już za tydzień.
Cześć!
Icon made by Freepik, Smashicons from www.flaticon.com


